Big Data Implementation
A Practical Guide
Working with big data technologies since 2013, ScienceSoft designs and implements secure and scalable big data solutions for businesses in 30+ industries. Here, we share our experience and dwell on key implementation steps, required talents, pricing, cost factors, and benefits of big data solutions.

Contributors

Principal Architect, AI & Data Management Expert, ScienceSoft

Senior Healthcare IT & AI Consultant, ScienceSoft
Big Data Solution Implementation: The Essence
Big data implementation gains strategic importance across all major industry sectors, helping mid-sized and large organizations successfully handle the ever-growing amount of data for operational and analytical needs. When properly developed and maintained, big data solutions efficiently accommodate and process petabytes of XaaS users' data, enable IoT-driven automation, facilitate advanced analytics to boost enterprise decision making, and more.
|
|
|
|
|
Note: Big data techs are essential for efficient processing and analytics of continuously arriving, often unstructured data (e.g., texts, images, video, audio) that is not necessarily large in volume. In some cases, even petabyte-scale data is better to be managed with traditional techs (e.g., when it’s structured, tabular data like financial and transactional data, customer demographics). Does your data combine large volume and low complexity? Then you are most likely to benefit from data warehouse implementation. Check our dedicated DWH implementation guide. |
|
|
|
Key steps of big data implementation
- Formulate and plan the concept.
- Design the architecture.
- Develop and perform QA.
- Deploy the solution.
- Provide support and maintenance.
Read our detailed guide on big data implementation below.
Required team: Project manager, business analyst, big data architect, big data developer, data engineer, data scientist, data analyst, DataOps engineer, DevOps engineer, QA engineer, test engineers. Check typical roles on ScienceSoft's big data teams.
Costs: from $200,000 to $3,000,000 for a mid-sized organization, depending on the project scope. Use a online calculator below to estimate the cost for your case.
Since 2013, ScienceSoft has been designing and building efficient and resilient big data solutions with scalable architectures that withstand extreme concurrency, request rates, and traffic spikes.
Key Components of a Big Data Solution
Below, ScienceSoft’s big data experts provide an example of a high-level big data architecture and describe its key components.
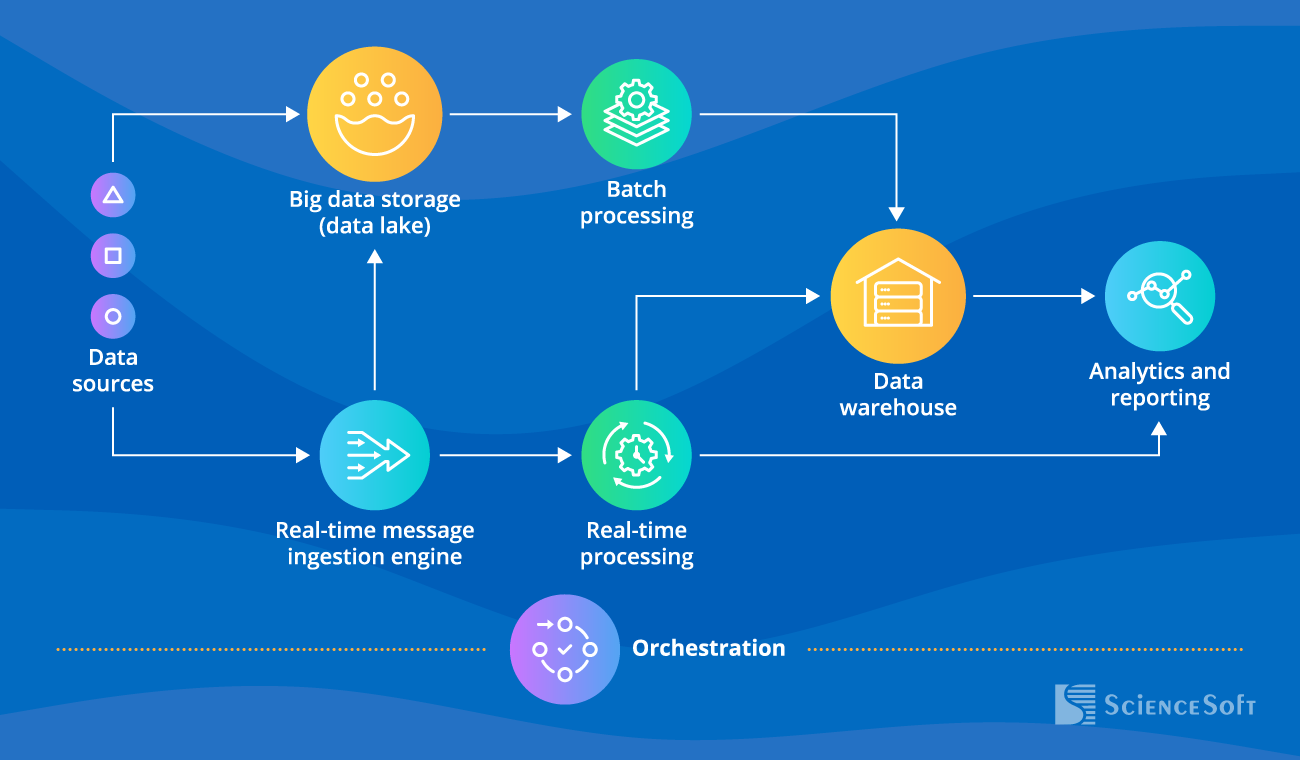
-
Data sources provide real-time data (e.g., from payment processing systems, IoT sensors) and historical data (e.g., from relational databases, web server log files, etc.).
- Data storage (a data lake) holds multi-source voluminous data in its initial format (structured, unstructured, and semi-structured) for further batch processing.
-
A stream ingestion engine captures real-time messages and directs them to the real-time (stream) processing module and the data lake (the latter stores this data to ensure its in-depth analytics during further batch processing).
Batch processing engine
Best for: repetitive non-time-sensitive jobs that facilitate analytics tasks (e.g., billing, revenue reports, daily price optimization, demand forecasting).
- Deals with large datasets.
- The results are available as per the established computation schedule (e.g., every 24 hours).
Stream processing engine
Best for: tasks that require an immediate response (e.g., payment processing, traffic control, personalized recommendations on ecommerce websites, burglary protection systems).
- Deals with small data chunks.
- The processed data is always up-to-date and ready for immediate use due to low latency (milliseconds to seconds).
|
|
Note: Depending on your big data needs, a specific solution might enable only batch or only stream data processing, or combine both types as shown in the sample architecture above. |
- Once processed, data can go to a data warehouse for further analytical querying or directly to the analytics modules.
- Lastly, the analytics and reporting module helps reveal patterns and trends in the processed data, then use these findings to enhance decision-making or automate certain complex processes (e.g., management of smart cities).
- With orchestration that acts as a centralized control to data management processes, repeated data processing operations get automated.
Big Data Implementation Steps
Real-life big data implementation steps may vary greatly depending on the business goals a solution is to meet, data processing specifics (e.g., real-time, batch processing, both), etc. However, from ScienceSoft’s experience, there are six universal steps that are likely to be present in most projects.
Step 1.
Feasibility study

Analyzing business specifics and needs, validating the feasibility of a big data solution, calculating the estimated cost and ROI for the implementation project, assessing the operating costs.
Big data initiatives require a thorough feasibility investigation to avoid unnecessary expenses. To ensure that each dollar spent brings our clients real value, ScienceSoft's big data consultants prepare a comprehensive feasibility report featuring tangible gains and possible risks.


Step 2.
Requirements engineering and big data solution planning

- Defining the types of data (e.g., SaaS data, SCM records, operational data, images and video) to be collected and stored, the estimated data volume, and the required data quality metrics.
- Forming a high-level vision of the future big data solution, outlining:
- Data processing specifics (batch, real-time, or both).
- Required storage capabilities (data availability, data retention period, etc.).
- Integrations with the existing IT infrastructure components (if applicable).
- The number of potential users.
- Security and compliance (e.g., HIPAA, PCI DSS, GDPR) requirements.
- Analytics processes to be introduced to the solution (e.g., data mining, ML-powered predictive analytics).
- Choosing a deployment model: on-premises vs. cloud (public, private) vs. hybrid.
- Selecting an optimal technology stack.
- Preparing a comprehensive project plan with timeframes, required talents, and budget outlined.
ScienceSoft can provide you with expert guidance on all aspects of big data planning.
Step 3.
Architecture design

- Creating the data models that represent all data objects to be stored in big data databases, as well as associations between them, to get a clear picture of data flows, the ways data of certain formats will be collected, stored, and processed in the solution-to-be.
- Mapping out data quality management strategy and data security mechanisms (data encryption, user access control, redundancy, etc.).
- Designing the optimal big data architecture that enables data ingestion, processing, storage, and analytics.
Statista projects that global data generation could triple in just four years (2025–2029). As businesses expand, the number of data sources and the overall data volume inevitably grow as well. This makes scalable architecture the cornerstone of efficient big data implementation that can save you from costly redevelopments down the road.

Step 4.
Big data solution development and testing

- Setting up the environments for development and delivery automation (CI/CD pipelines, container orchestration, etc.).
- Building the required big data components (e.g., ETL pipelines, a data lake, a DWH) or the entire solution using the selected techs.
- Implementing data security measures.
- Performing quality assurance in parallel with development. Conducting comprehensive testing of the big data solution, including functional, performance, security and compliance testing. If you’re interested in the specifics of big data testing process, see expert guide by ScienceSoft.
Since 1989 in software engineering and since 2013 in big data, ScienceSoft is ready to help you develop and deploy your big data software.
Step 5.
Big data solution deployment

- Preparing the target computing environment and moving the big data solution to production.
- Setting up the required security controls (audit logs, intrusion prevention system, etc.).
- Launching data ingestion from the data sources, verifying the data quality (consistency, accuracy, completeness, etc.) within the deployed solution.
- Running system testing to validate that the entire big data solution works as expected in the target IT infrastructure.
- Selecting and configuring big data solution monitoring tools, setting alerts for the issues that require immediate attention (e.g., server failures, data inconsistencies, overloaded message queue).
- Delivering user training materials (FAQs, user manuals, a knowledge base) and conducting Q&A sessions and trainings, if needed.
Step 6.
Support and evolution (continuous)

- Establishing support and maintenance procedures to ensure trouble-free operation of the big data solution: resolving user issues, refining the software and network settings, optimizing computing and storage resources utilization, etc.
- Evolution may include developing new software modules and integrations, adding new data sources, expanding the big data analytics capabilities, introducing new security measures, etc.
Big Data Solution Implementation Costs

The cost of end-to-end implementation of a big data solution may vary from $200,000 to $3,000,000 for a mid-sized organization, depending on data variety and complexity, data processing specifics, business objectives, the chosen sourcing model, and more. The number of big data solution modules is one of the defining cost factors and can condition a cost above the range stated before.
Want to find out the cost of your big data project?
Estimate the Cost of Big Data Implementation
Please answer a few questions about your business needs to help our experts estimate your service cost quicker.

Thank you for your request!
We will analyze your case and get back to you within a business day to share a ballpark estimate.
In the meantime, would you like to learn more about ScienceSoft?
- Project success no matter what: learn how we make good on our mission.
- In data management and analytics since 1989: check what we do.
- 4,300+ successful projects: explore our portfolio.
- 1,500+ incredible clients: read what they say.

Sourcing Models for Big Data Solution Implementation
![]()
In-house big data solution development
- Full control over the project.
- Possible lack of talents with required skills, insufficient team scalability.
- All managerial efforts are on your side.
![]()
Team augmentation
- On-demand availability of talents with the required skills.
- Sufficient control over the project.
- Extra efforts to achieve smooth cooperation between the teams.
![]()
Outsourced big data solution development
- A fully managed & experienced big data team.
- Established best practices for big data implementation.
- A quick project start.
- Risks of choosing an inept vendor.
Why Choose ScienceSoft for Big Data Implementation
- In big data solutions development since 2013.
- In data analytics and data science since 1989.
- Experience in 30+ industries, including healthcare, insurance, investment, banking, lending, retail, ecommerce, professional services, manufacturing, transportation and logistics, energy, telecoms, and more.
- 750+ experts on board, including big data solution architects, DataOps engineers, and ISTQB-certified QA engineers.
- Strong Agile and DevOps culture.
- ISO 9001 and ISO 27001 certified to ensure robust quality management system and the security of the customers' data.





Our Clients Say

Garan’s operations largely depend on timely analytical insights, so when the performance of our big data reporting solution decreased dramatically, we needed to fix the problem as quickly as possible. ScienceSoft’s consulting on Hadoop and Spark made a tremendous difference. The changes we made on their advice helped our data processing speed drop from hours to minutes.


ScienceSoft has delivered cutting-edge solutions to complex problems bringing in innovative ideas and developments.
ScienceSoft follows specifications very rigidly, requiring clear communication about intended functionality. My final comment about ScienceSoft reflects their dedication to handle any problem that occurs as a result of hardware or software issues; simply put, they will go the extra mile to support their customers regardless of the time of day these issues arise.

We needed a proficient big data consultancy to deploy a Hadoop lab for us and to support us on the way to its successful and fast adoption.
ScienceSoft's team proved their mastery in a vast range of big data technologies we required: Hadoop Distributed File System, Hadoop MapReduce, Apache Hive, Apache Ambari, Apache Oozie, Apache Spark, Apache ZooKeeper are just a couple of names. Whenever a question arose, we got it answered almost instantly.


Typical Roles on ScienceSoft’s Big Data Teams
With 750+ professionals on board, ScienceSoft has experts to cover any project scope. Below, we describe key roles in our big data projects teams that can also be augmented with our front-end developers, UX and UI designers, BI engineers, and other professionals.
![]()
Project manager
Plans and oversees a big data implementation project; ensures compliance with the timeframes and budget; reports to the stakeholders.
![]()
Business analyst
Analyzes the business needs or app vision; elicits functional and non-functional requirements; verifies the project’s feasibility.
![]()
Big data architect
Works out several architectural concepts to discuss them with the project stakeholders; creates data models; designs the chosen big data architecture and its integration points (if needed); selects the tech stack.
![]()
Big data developer
Assists in selecting techs; develops big data solution components; integrates the components with the required systems; fixes code issues and other defects on a QA team’s notices.
![]()
Data engineer
Assists in creating data models; designs, builds, and manages data pipelines; develops and implements a data quality management strategy.
![]()
Data scientist
Designs the processes of data mining; designs ML models; introduces ML capabilities into the big data solution; establishes predictive and prescriptive analytics.
![]()
Data analyst
Assists a data engineer in working out a data quality management strategy; selects analytics and reporting tools.
![]()
DataOps engineer
Helps streamline big data solution implementation by applying DevOps practices to the big data pipelines and workflows.
![]()
DevOps engineer
Sets up the big data solution development infrastructure; introduces CI/CD pipelines to automate development and release; deploys the solution into the production environment; monitors solution performance, security, etc.
![]()
QA engineer
Designs and implements a quality assurance strategy for a big data solution and high-level testing plans for its components.
![]()
Test engineer
Designs and develops manual and automated test cases to comprehensively test the operational and analytical parts of the big data solution; reports on the discovered issues found and validates the fixed defects.
The Benefits of Implementing Big Data with ScienceSoft
![]()
Improved business processes
Having practical experience in 30+ industries, we know how to create solutions that not only fit our clients' unique processes but improve them.
![]()
Top-notch UX
We build easy-to-navigate interfaces, create informative visuals, and implement self-service capabilities to make data exploration and presentation a smooth experience, even for non-technical users.
![]()
Complete security
With our ISO 27001-certified security management system and zero security breaches in the company's entire 36-year history, we can guarantee full protection of your big data software.
![]()
Focus on future-proofing
We build big data systems that preserve stable performance from day one and can be easily scaled and upgraded to accommodate any data volume increase or ensure new capabilities in the future.
![]()
Vendor neutrality
We are proficient in 50+ big data techs and hold official partnerships with Microsoft and AWS. So, when we choose the techs, we are guided only by the value they will drive in every particular project.
Technologies ScienceSoft Uses to Develop Big Data Solutions
Distributed storage
Database management
Amazon DocumentDB
Apache Hive
Apache HBase
Apache NiFi
MongoDB
Microsoft Fabric
Google Cloud Datastore
Data management
Apache Airflow
Talend
Informatica
Zaloni
Apache ZooKeeper
Azkaban
Data streaming and stream processing
Microsoft Fabric
Apache KafkaApache NiFi
Apache SparkApache Storm
Azure IoT Hub
Azure Stream Analytics
Amazon Kinesis
Batch processing
MapReduce
Amazon EMR
Apache Hive
Pig
Data warehouse, ad hoc exploration and reporting
PostgreSQL
Azure Synapse Analytics Amazon Redshift Power BIMicrosoft Fabric
Tableau
QlikView
Google Developers Charts
Grafana
Sisense
Machine learning
MATLAB
GNU Octave
R
Apache Mahout
Caffe
Apache MXNet
Microsoft Fabric
TensorFlow
Keras
Torch
OpenCV
Theano
Apache Spark MLlib
Scikit Learn
Gensim
SpaCy
Amazon Machine Learning
Amazon SageMaker AI
Azure Machine Learning
Google Cloud AI Platform
Einstein
Implement a Big Data Solution with Professionals
With 37 years in IT and 13 years in big data services, ScienceSoft can design, build, and support a state-of-the-art big data solution or provide assistance at any stage of big data implementation. With established practices for scoping, cost estimation, risk mitigation, and other project management aspects, we drive project success regardless of time and budget constraints, as well as changing requirements.

Consulting on big data implementation
Get expert guidance at any step of your big data initiative. ScienceSoft is ready to provide you with a wide scope of deliverables, including a business case, a detailed project roadmap, an architecture design, and a PoC to help you eliminate doubt and avoid unnecessary expenses.

Big data solution development
We're ready to deliver big data software of any complexity to let you benefit from a solution that is tailored to your specific needs and runs smoothly at any data and user loads. If needed, you can also count on us to stay with you for continuous maintenance and support.
About ScienceSoft
ScienceSoft is a global IT consulting and software development company headquartered in McKinney, TX. Since 2013, we have been delivering end-to-end big data services to businesses in 30+ industries. Being ISO 9001 and ISO 27001 certified, we ensure robust quality management system and full security of our clients’ data.
