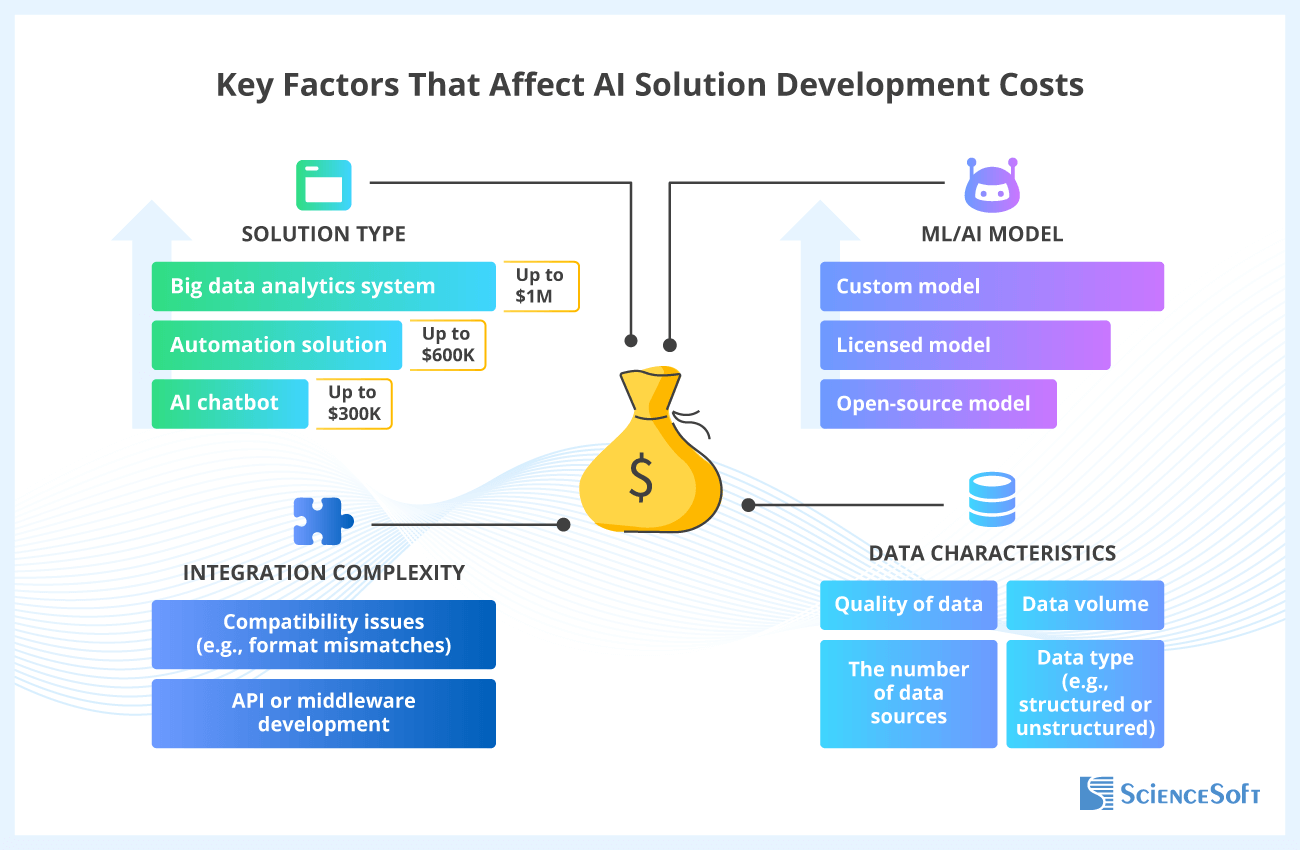
For most business cases, training an AI model from scratch isn’t necessary. The fastest path is to start with proven foundation models (open-source or commercial), adapt them with prompt engineering and RAG, and validate the use case through experiments, a PoC, or an MVP to confirm what works. Open-source models are usually more cost-effective and flexible, while commercial platforms often make scaling, governance, and support easier. You can also combine several models: in one project, we used five open-source NLP models to add smart features to a help desk system.
As adoption grows, the key trade-off becomes speed vs. cost at scale: start fast with foundation models, then scale efficiently with smaller expert models (SLMs). When usage is high, paying for a large general-purpose model on every request can get expensive. A smaller, task-specific SLM that is fine-tuned or distilled for your domain often delivers comparable results for well-defined, repeatable tasks while keeping costs under control.
Build a fully custom model only when you truly need maximum control over accuracy, latency, or data privacy (e.g., medical diagnostics, credit risk scoring, fraud detection, manufacturing quality control). Even then, it’s usually more efficient to fine-tune or distill an existing model than to build a new one end to end.