Enterprise Data Lake
Architecture, Tech Stack, Use Cases
In big data since 2013, ScienceSoft builds secure and scalable data lakes to help businesses across 30+ industries efficiently store, manage and analyze ever-growing volumes of enterprise data.

Enterprise Data Lake Adoption
The enterprise data lake market was estimated at $18.68 billion in 2025 and is expected to reach $51.78 billion by 2030, at a CAGR of 22.62%.
The main use cases for enterprise data lakes
- Aggregation and storage of massive datasets, including XaaS data, clickstream data, sensor readings and other IoT data, etc.
- Data science and advanced analytics: the voluminous data stored in a data lake can be used for further exploration and analysis (e.g., for data warehousing and exploratory data analysis).
- Serving operational applications driven by real-time data, such as recommendation engines and fraud detection tools.
What Is an Enterprise Data Lake?
An enterprise data lake is a flexible centralized repository for enterprise data in its raw format: structured, semi-structured, or unstructured. With this solution, companies don't have to discard enterprise data just because there is no clear business use for it yet: a lake makes it possible to store voluminous data cost-efficiently and use it for in-depth analysis when needed.
Enterprise Data Lake Architecture: Key Zones
Depending on the data management objectives and the tech systems already in place, an enterprise data lake can be used not only for data storage but also for data transformation and processing.
NB! A data lake is not supposed to compete with or replace an enterprise data warehouse – on the contrary, the tech solutions work best when they complement each other. To learn more about the differences between these two types of systems, check out a dedicated article by Alex Bekker, Principal Architect, AI & Data Management Expert at ScienceSoft.
Below, we outline a sample architecture of an enterprise data lake, which is organized into four major zones.
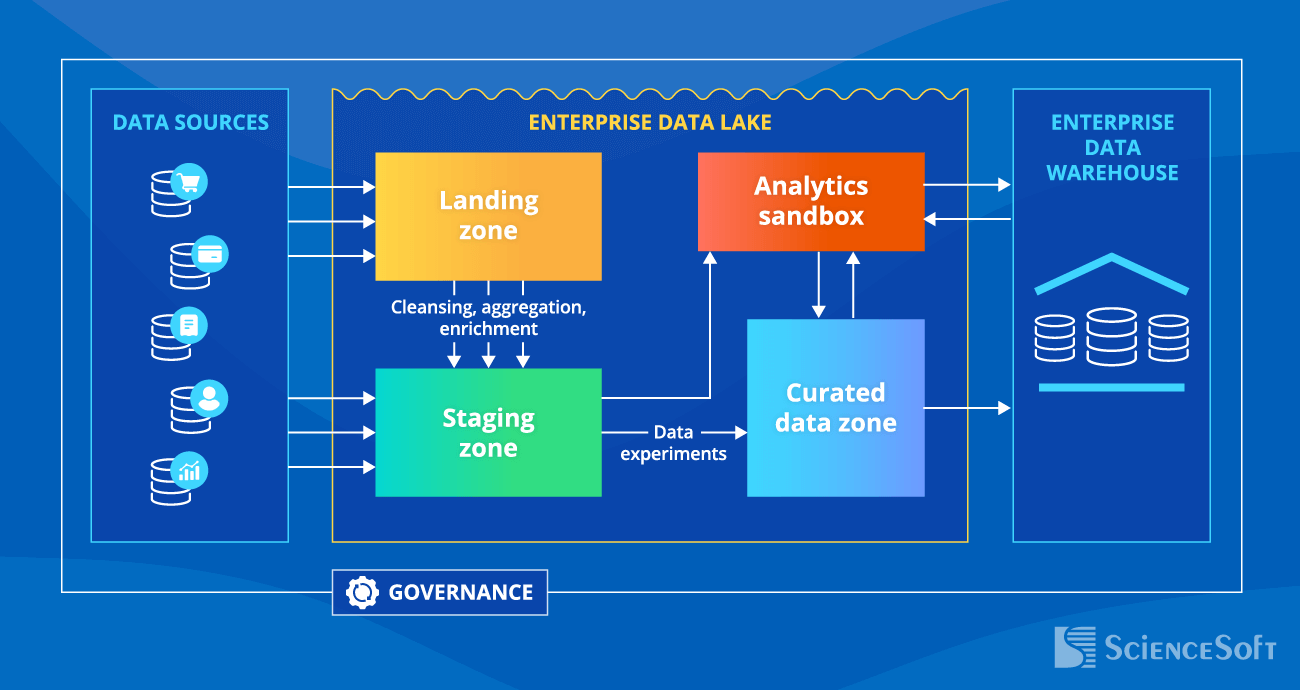
- A landing zone holds raw data ingested from multiple data sources. Only data engineers and data scientists can access this zone.
- A staging zone is present when primary data normalization is needed. Here, raw data from the landing zone gets cleaned (e.g., erroneous readings from IoT sensors are filtered out). Plus, the staging zone can ingest data from external or internal sources if it doesn't require preprocessing (e.g., customer reviews from an ecommerce website).
- An analytics sandbox is a secure environment that allows data scientists to explore the data, try different approaches to analysis and assess the results, build and test ML models to experiment with large datasets without affecting the production environment.
- A curated data zone stores cleansed, processed data converted into conforming dimensions or master lists (e.g., organizing the street number and name, apartment unit, city, zip code, and country into a single address field). With custom scripts or data quality and ETL tools, cleansing operations can be more sophisticated: e.g., data verification and handling conflicting information from different data sources.
NB! As the curated data zone stores processed data, it is sometimes considered a part of an enterprise data warehouse. Still, for some use cases requiring large-scale queries with access to data details (e.g., predictive maintenance, fraud detection, customer segmentation), running the entire analytical process in the data lake ensures speed and cost-efficiency.

Enterprise data lakes tend to become data swamps if not managed properly. Thus, when architecting a data lake, it's imperative to plan out robust data governance, including security and metadata management policies and processes.
Reliable Technologies and Tools We Use to Develop Enterprise Data Lakes
Data ingestion
- Apache Kafka
- Apache NiFi
- Azure IoT Hub
- Azure Event Hubs
- AWS IoT Core
- RabbitMQ
Data storage
- HDFS
- Amazon S3
- Azure Data Lake
- Azure Blob Storage
- Azure Files
Data governance
- Apache Airflow
- Talend
- Informatica
- Zaloni
- Apache ZooKeeper
- Azkaban
Data security
- AWS Cloud Security services
- Azure Security services
ScienceSoft: Here To Help You Turn Enterprise Data into a Valuable Asset
- In data analytics and data science since 1989.
- Working with big data since 2013.
- A team of 750+ enthusiastic IT professionals, including solution architects and data engineers with 7–20 years of experience.
- Enterprise data lake engineering services for 30+ industries, including healthcare, insurance, investment, banking, lending, retail, ecommerce, professional services, manufacturing, transportation and logistics, energy, telecommunications, and more.
- An in-house PMO and mature project management practices to handle large-scale projects and achieve project goals regardless of time and budget constraints.
- A quality-first approach based on a mature ISO 9001-certified quality management system.
- ISO 27001-certified security management to guarantee complete security of our clients' data.





Consider Professional Services for Your Enterprise Data Lake Journey
Relying on 37 years in data analytics and 13 years in big data, ScienceSoft can help you design a solid data lake architecture, join you at any stage of enterprise data lake engineering, or take over its end-to-end implementation.

Enterprise data lake consulting
ScienceSoft's experts will map out an efficient enterprise data management strategy, plan a secure and resilient architecture for your data lake, help you choose the best-fitting tech stack, and prepare a detailed project roadmap with valuable advice on risk mitigation for each step.

Enterprise data lake development
ScienceSoft is ready to deliver a turnkey enterprise data lake solution, covering everything from architecture design to QA and secure deployment. We also offer long-term support to ensure unfailing data lake performance and smoothly tune it to your evolving data management needs.
3 Things That Become Possible with an Enterprise Data Lake
|
|
More data, cheaper storage. Unlike traditional databases or data warehouses, enterprise data lakes can cost-efficiently accommodate heterogeneous data at any scale. |
|
|
Safe data experiments. Data scientists and engineers can run experiments in an analytics sandbox without affecting the production environment. |
|
|
Easy adoption of advanced technologies such as ML and AI for predictive analytics, fraud detection, image analysis, and more. |

