NoSQL Databases: Defined and Explained


Alex Williams is a seasoned full-stack developer and the owner of Hosting Data UK. After graduating from the University of London, majoring in IT, Alex worked as a developer leading various projects for clients from all over the world for almost 10 years. Recently, Alex switched to being an independent IT consultant and started his own blog. He explores web development, data management, digital marketing, and solutions for budding online business owners.
Related topics:
5 min read
Last updated:
Editor’s note: Alex overviews NoSQL databases, their major benefits and limitations, and outlines the most popular NoSQL database typology. In case you need expert help with developing a high-performing NoSQL database, check ScienceSoft’s offering in database development services.
If you’ve been around databases for a considerable amount of time, you’re familiar with SQL databases. They generally have a rigid structure due to their schemas and are only vertically scalable, meaning you can only increase performance by buying expensive hardware.
SQL excels at reducing duplicate content, which helps keep the cost of storage down. It was great during the 1970s, 1980s, and 1990s, when storage came at an expensive premium, but not so much in the 2000s, 2010s, and beyond, when storage is ridiculously cheap.
As such, there was no real reason to stick to the constraints of SQL, and that’s how NoSQL was born.
NoSQL (aka ‘not only SQL’) databases can store and retrieve data that is modeled other than the tabular relations in SQL databases, which makes them particularly useful for managing big data.
Advantages of NoSQL
Flexibility
NoSQL databases are essentially freeform as they don’t use a schema, and they aren’t relational. This NoSQL characteristic is due to design rather than a specific language created to deal with database management, so you can use several different data models with NoSQL, depending on your needs.
Scale-out architecture
NoSQL is horizontally scalable, which means you don’t need to buy expensive hardware but can simply throw another shard in, and you’re good to go. As a result, NoSQL is essentially infinitely scalable depending on how far you need to take it, with the expansion itself being relatively easy.
Reduced development costs
Since NoSQL doesn’t generally use a schema, there’s no need to hire a schema designer. You also don’t have to worry about adding new fields or data types since you can pretty much mix and match things to your heart’s desire making the database design process less tedious. Thus, you’ll have easier database setup, rollout, and day-to-day maintenance and use.
Challenges of NoSQL
Data consistency
The primary drawback is that many NoSQL databases compromise consistency. While most relational databases abide by ACID principles (Atomicity, Consistency, Isolation, Durability), the same can be said only about a small percentage of popular NoSQL databases (e.g., Azure Cosmos DB, Amazon DynamoDB). In layman’s terms, an ACID guarantee means that the database you’re using won’t lose any data unless intended.
Lack of development talents
NoSQL is not as widely used as SQL, so there aren’t many NoSQL experts lying around idly. Combine that with the fact that there is a considerable number of different NoSQL data models to be knowledgeable about, and you’re looking at an uphill climb finding experts.
For the most part, you’ll have to rely on smaller expert communities and the database’s own documentation to get answers to any arising questions.
Scalability
Another issue is that NoSQL takes up a ton of storage since it ignores data duplication (and sometimes requires it by definition). Likely you’ll end up needing an order of magnitude of storage higher than an SQL database. However, as data storage is relatively cheap nowadays, this need won’t impact you too much in the long run.
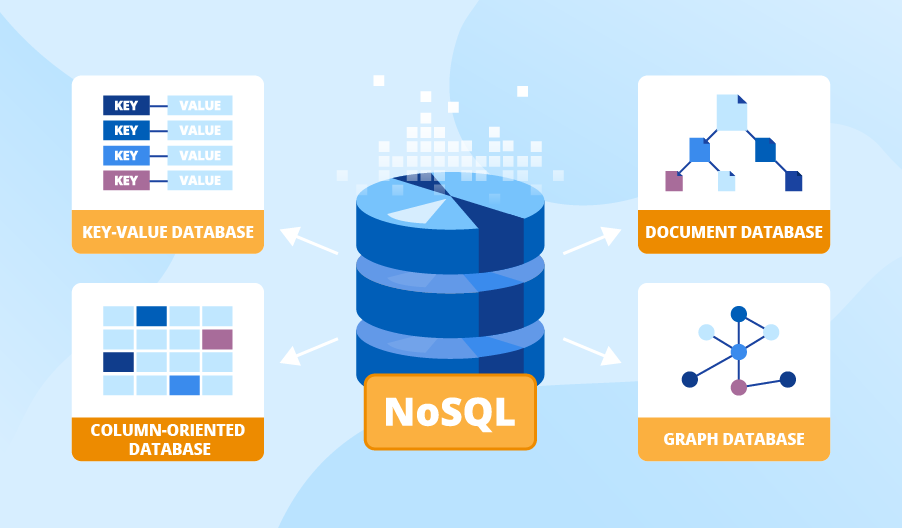
Types of NoSQL Databases
While there are several dozen NoSQL databases, they essentially rely on only a few data models.
Key-Value Store
Key-value stores use a hash table that stores a pointer, which is the key, which then points to a value that stores some form of information or data. Ergo the name, key-value!
This type of data model is really versatile due to the fact that data can be a mix and match of pretty much anything, so you can find a database to fit any specialized needs. No wonder key-value stores are considered one of the most popular data models for NoSQL databases.
Moreover, key-value stores are excellent for high-performance and/or high-volume use cases. For example, the key-value database DynamoDB manages to serve millions of people across the globe nearly every second.
Column-oriented
Rather than storing the data in a row, this type of data model stores information in columns nestled inside other families of columns. Imagine columns, inside groups, inside columns.
Since data is contained in such an efficient manner, column-oriented databases have great data aggregation capabilities and data access performance. On the flip side, complex querying certainly becomes a letdown.
Document Stores
Document stores don’t tie XML and JSON together in the traditional way SQL would. And when these two are uncoupled from each other, they can perform at peak efficiency not forced to go as fast as the slowest denominator. There are even some NoSQL databases specifically made for XML, which is neat.
Interestingly enough, document stores are sometimes considered a sub-type of key-value stores, but this data model subtype is big enough to get its own section. Part of its popularity is its flexibility since you can throw in any data type you want.
Graph
As you might have guessed by the name of this data model, it is perfect for a database that represents information in graph form.
With this data model type, information is stored as both nodes and edges. More specifically, the nodes store such information as addresses, names, dates, and so forth, whereas the edges describe the relationships between the different nodes. It allows graph data models to show the relationships between often disparate sets of data, helping you tease out relevant and useful information.
Time to let your business grow with NoSQL
NoSQL databases can be incredibly powerful, though they aren’t cut out for replacing SQL. In fact, they’re meant to work with and complement SQL databases. If you need any assistance with designing, developing, and integrating a NoSQL database into your analytics or development environment, reach out to ScienceSoft’s team.
