Cassandra vs. HBase: twins or just strangers with similar looks?

Related topics:
Last updated:
Apache Cassandra and Apache HBase are much like two strangers whom you meet in the street and think to be twins. You don’t really know them, but their similar height, clothes and hairstyles make you see no differences between them. However, after having a closer look, you realize that these two looked identical only at a distance.
Having numerous similarities, like being NoSQL wide-column stores and descending from BigTable, Cassandra and HBase do differ. For instance, HBase doesn’t have a query language, which means that you’ll have to work with JRuby-based HBase shell and involve extra technologies like Apache Hive, Apache Drill or something of the kind. While Cassandra can boast its own CQL (Cassandra Query Language), which Cassandra specialists find most helpful.

1. Data model
HBase
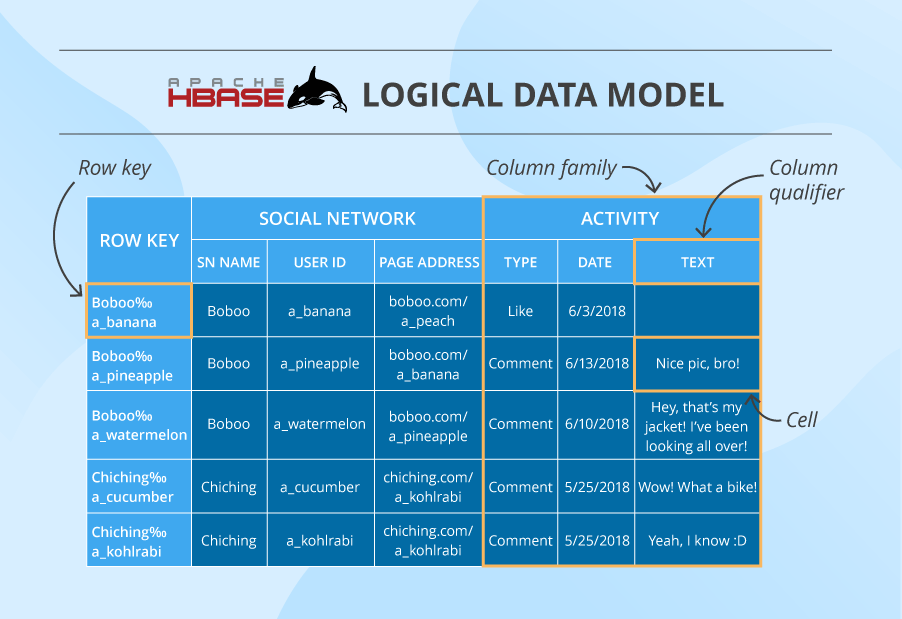
Here we have a table that consists of cells organized by row keys and column families. Sometimes, a column family (CF) has a number of column qualifiers to help better organize data within a CF.
A cell contains a value and a timestamp. And a column is a collection of cells under a common column qualifier and a common CF.
Within a table, data is partitioned by 1-column row key in lexicographical order, where topically related data is stored close together to maximize performance. The design of the row key is crucial and has to be thoroughly thought through in the algorithm written by the developer to ensure efficient data lookups.
Cassandra
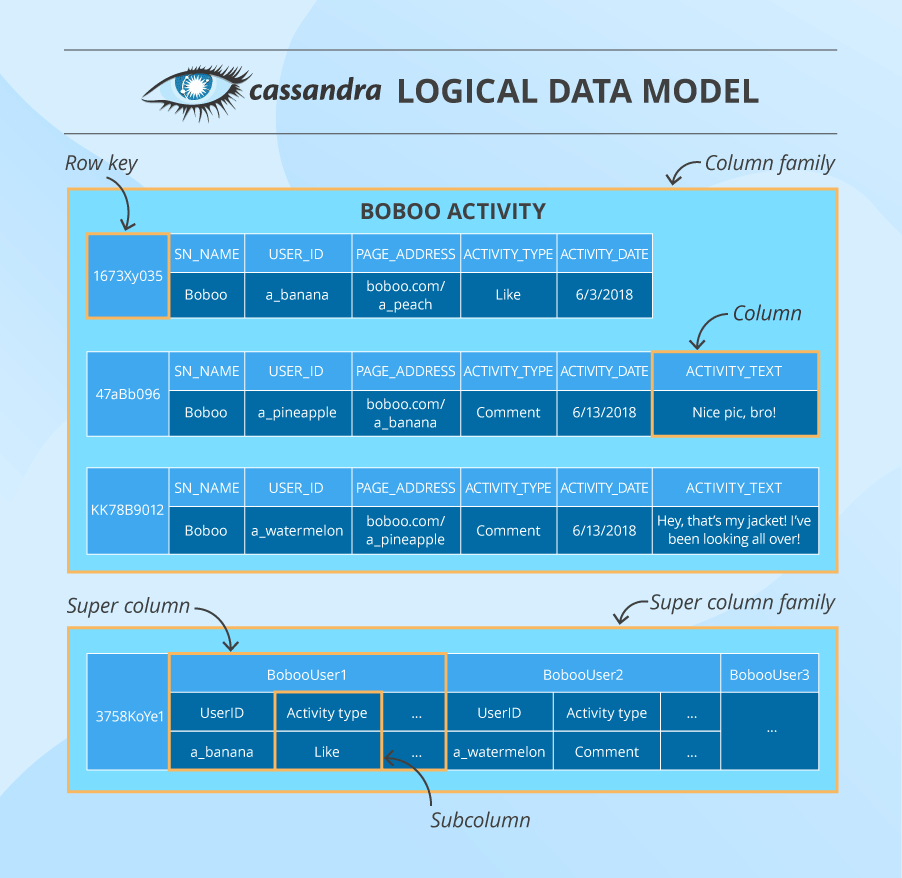
Here we have a column family that consists of columns organized by row keys. A column contains a name/key, a value and a timestamp. In addition to a usual column, Cassandra also has super columns containing two or more subcolumns. Such units are grouped into super column families (although these are rarely used).
In the cluster, data is partitioned by a multi-column primary key that gets a hash value and is sent to the node whose token is numerically bigger than the hash value. Besides that, the data is also written to an additional number of nodes that depends on the replication factor set by Cassandra practitioners. The choice of additional nodes may depend on their physical location in the cluster.
HBase vs. Cassandra (data model comparison)
The terms are almost the same, but their meanings are different. Starting with a column: Cassandra’s column is more like a cell in HBase. A column family in Cassandra is more like an HBase table. And the column qualifier in HBase reminds of a super column in Cassandra, but the latter contains at least 2 subcolumns, while the former – only one.
Besides, Cassandra allows for a primary key to contain multiple columns and HBase, unlike Cassandra, has only 1-column row key and lays the burden of row key design on the developer. Also, Cassandra’s primary key consist of a partition key and clustering columns, where the partition key also can contain multiple columns.
Despite these ‘conflicts,’ the meaning of both data models is pretty much the same. They have no joins, which is why they group topically related data together. They both can have no value in a certain cell/column, which takes up no storage space. They both need to have column families specified while schema design and can’t change them afterwards, while allowing for columns’ or column qualifiers’ flexibility at any time. But, most importantly, they both are good for storing big data.
2. Architecture
Cassandra has a masterless architecture, while HBase has a master-based one. This is the same architectural difference as between Cassandra and HDFS.
This means that HBase has a single point of failure, while Cassandra doesn’t. An HBase client does communicate directly with the slave-server without contacting the master, which gives the cluster some working time after the master goes down. But, this can hardly compete with the always-available Cassandra cluster. So, if you can’t afford any downtimes, Cassandra is your choice.
However, to ensure availability, Cassandra replicates and duplicates data, which leads to data consistency problems. This makes Cassandra a bad choice if your solution depends heavily on data consistency, unlike the strongly consistent HBase. Because the latter writes data only to one place and always knows where to find it (data replication is done ‘externally’ in HDFS).
Besides, Cassandra’s architecture supports both data management and storage, while HBase’s architecture is designed for data management only. By its nature, HBase relies heavily on other technologies, such as HDFS for storage, Apache Zookeeper for server status management and metadata. And again, it needs extra technologies to run queries.
3. Performance
-
Write
Cassandra’s and HBase’s on-server write paths are very much alike. There’re only slight differences: names for data structures and the fact that, unlike Cassandra, HBase doesn’t write to the log and cache simultaneously (it makes writes slower).
On the higher architectural level, HBase has even more disadvantages:
- Before getting to the needed server, the client has to ‘ask’ Zookeeper which server has the hbase:meta table containing info about all tables’ locations in the cluster. Then, the client asks the meta-table-holding server ‘who’ stores the actual table it needs to write to. And only after that the client writes the data to the needed place. If such writes (and also reads) are frequent, this info is of course cached. But if a table region is moved to another server, the client needs to do the full round again. While Cassandra’s data distribution and partitioning based on consistent hashing is much cleverer and quicker than that.
- As soon as the in-HBase write path ends (cached data gets flushed to the disk), HDFS also needs time to physically store the data.
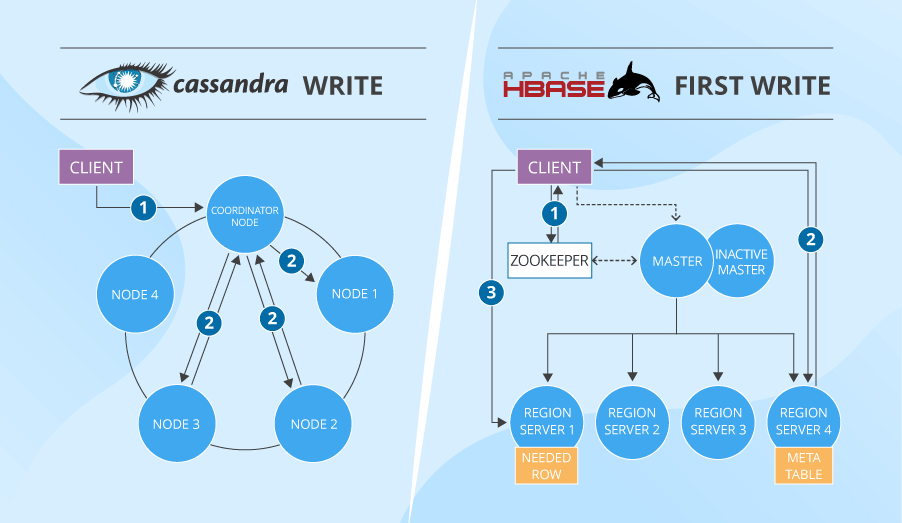
Moreover, the actual measurements of Cassandra’s write performance (in a 32-node cluster, almost 326,500 operations per second versus HBase’s 297,000) also prove that Cassandra is better at writes than HBase.
-
Read
If you need lots of fast and consistent reads (random access to data and scans), then you can opt for HBase. It writes only on one server, so there is no need to compare different nodes’ data versions. HBase servers also don’t have too many data structures to check before finding your data. You may think that HBase’s read is inefficient since the data is actually stored in HDFS, and HBase needs to get it out of there every time. But HBase has a block cache that has all frequently accessed HDFS data, plus bloom filters with all other data’s approximate ‘addresses,’ which speeds up data retrieval. Essentially, HBase and HDFS’s index system is multi-layered, which is much more efficient than Cassandra’s indexes (check out our article on Cassandra performance to find out more about reads).
If you’ve read that Cassandra is also very good at reads, you may be bewildered by the conclusion that HBase is better. Especially if you saw this benchmarking experience where Cassandra handles 129,000 reads per second against HBase’s just 8,000 (in a 32-node cluster). The thing is, these reads are targeted (based on known primary keys) and, chances are, they are also quite inconsistent. So, Cassandra’s huge numbers fade, if we’re speaking about scans and consistency.
4. Security
Like all NoSQL databases, HBase and Cassandra have their security issues (the main one being that securing data spoils performance making the system heavy and inflexible). But it’s safe to say that both databases have some features to ensure data security: authentication and authorization in both and inter-node + client-to-node encryption in Cassandra. HBase, in its turn, provides the much-needed means for secure communication with other technologies it relies upon.
A bit more detail:
Both Cassandra and HBase provide not just database-wide access control but allow a certain level of granularity. Cassandra enables row-level access and HBase goes as deep as cell-level. Cassandra defines user roles and sets conditions for these roles which later determine whether a user can see particular data or not. While HBase has an inverse ‘move.’ Its administrators assign a visibility label to data sets and then ‘tell’ users and user groups what labels they can see.
5. Application areas
Judging by how Cassandra and HBase organize their data models, they are both really good with time-series data: sensor readings in IoT systems, website visits and customer behavior, stock exchange data, etc. They both store and read such values nicely. Besides that, scalability is the property they both have: Cassandra – linear, HBase – linear and modular ones.
However, when it comes to scanning huge volumes of data to find a small number of results, due to having no data duplications, HBase is better. For instance, this reason applies to HBase’s ability to handle text analysis (based on web pages, social network posts, dictionaries and so on). Plus, HBase can do well with data management platforms and basic data analysis (counting, summing and such; due to its coprocessors in Java).
Cassandra is good for huge volumes of data ingestion, since it’s an efficient write-oriented database. With it, you’ll build a reliable and available data store. In addition, Cassandra enables you to create data centers in different countries and keep them running in sync. Besides, if you couple Cassandra with Spark, you can also achieve good scan performance.
But the main difference between applying Cassandra and HBase in real projects is this. Cassandra is good for ‘always-on’ web or mobile apps and projects with complex and/or real-time analytics. But if there’s no rush for analysis results (for instance, doing data lake experiments or creating machine learning models), HBase may be a good choice. Especially if you’ve already invested in Hadoop infrastructure and skill set.
Cassandra vs. HBase – a recap
Cassandra is a ‘self-sufficient’ technology for data storage and management, while HBase is not. The latter was intended as a tool for random data input/output for HDFS, which is why all its data is stored there. Besides, HBase uses Zookeeper as a server status manager and the ‘guru’ that knows where all metadata is (to avoid immediate cluster failures, when the metadata-containing master goes down). Consequently, HBase’s complex interdependent system is more difficult to configure, secure and maintain.
Cassandra is good at writes, whereas HBase is good at intensive reads. Cassandra’s weak spot is data consistency, while HBase’s pain is data availability, although both try to mitigate the adverse consequences of these problems. Also, both don’t stand frequent data deletes and updates.
So, Cassandra and HBase are definitely not twins but just two strangers with a similar hairstyle. To choose between the two, you should thoroughly analyze your tasks. And then, try to find a way to strengthen the database’s weak spots without affecting its performance.
