Big Data Processing
Architecture, Tech Stack, Examples
In software development since 1989 and in big data since 2013, ScienceSoft helps plan and build reliable and effective big data solutions and platforms.

99% of Firms Actively Invest in Big Data Initiatives
NewVantage Big Data and AI Survey revealed that 99% of mid-size and large companies already use big data and 92% of them are planning to accelerate their investments in the coming years.
Traditionally, big data solutions are analytics-focused and aimed at driving informed decision making. Though the share of operational big data solutions is steadily growing in line with the need to process petabytes of XaaS users' data or enable IoT-driven automation.
Popular big data processing use cases:
- Real-time vehicle tracking; traffic management; geofencing.
- Medical IoT.
- Credit card fraud/account takeover detection.
- Real-time stock market quotes management.
- Automated real-time anomaly recognition for manufacturing/oil&gas industries.
- Connected smart appliances.
- Online video games.
- XaaS
Big Data Processing: The Essence
Big data processing covers collecting, storing, and managing massive amounts of data (mostly in a semi- or unstructured form) that arrives from multiple sources. Big data processing stages include data ingestion into a data lake or a stream processing engine, data cleansing and transformation, and data loading into an analytics storage optimized for querying and reporting. Processed big data is used to derive insights (including real-time) and trigger immediate automated actions.
|
|
|
|
|
Key approaches: Batch processing and stream processing (also known as real-time processing, event streaming and complex event processing).
The demand for stream processing has grown significantly in recent years due to its ability to simplify data architectures, provide real-time insights, and support use cases involving time-sensitive data like asset monitoring, personalization, clickstream, and multi-player video games. Typical architecture modules: Data sources, a data bus, a stream processing component, a big data storage, batch processing, a data warehouse, and a big data governance component. Popular architecture options: Lambda, Kappa. |
|
|
|
Big Data Processing Architecture Options
ScienceSoft explains two architecture options that perfectly meet the needs of the majority of companies:
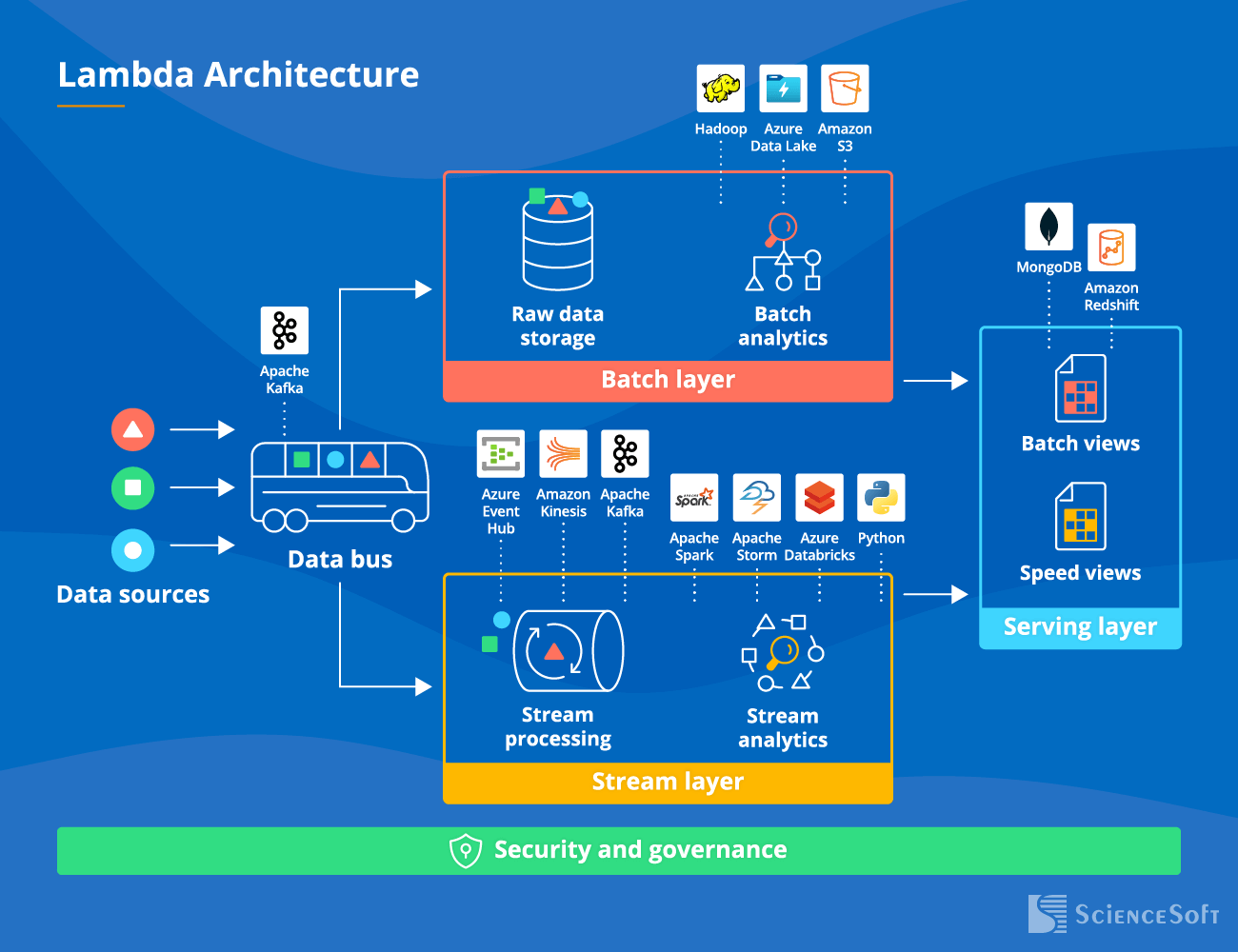
1. Lambda architecture
|
|
|
|
|
|
The essence: The Lambda architecture implies two separate data flows (= two technology stacks) – one for batch and the other for real-time processing. The complexity is to piece the output of these two flows together. |
|
|
|
|
|
Pros:
- Existing ETL processes can be used as the batch layer.
- High performance.
- A low possibility of errors even if the system crashes, as a separate distributed storage will keep historical data intact.
- Fewer data streams with indefinite time-to-live, thus, cheaper PaaS and IaaS services.
- Lower development cost since there's no need to rewrite algorithms (not all algorithms can be made streaming).
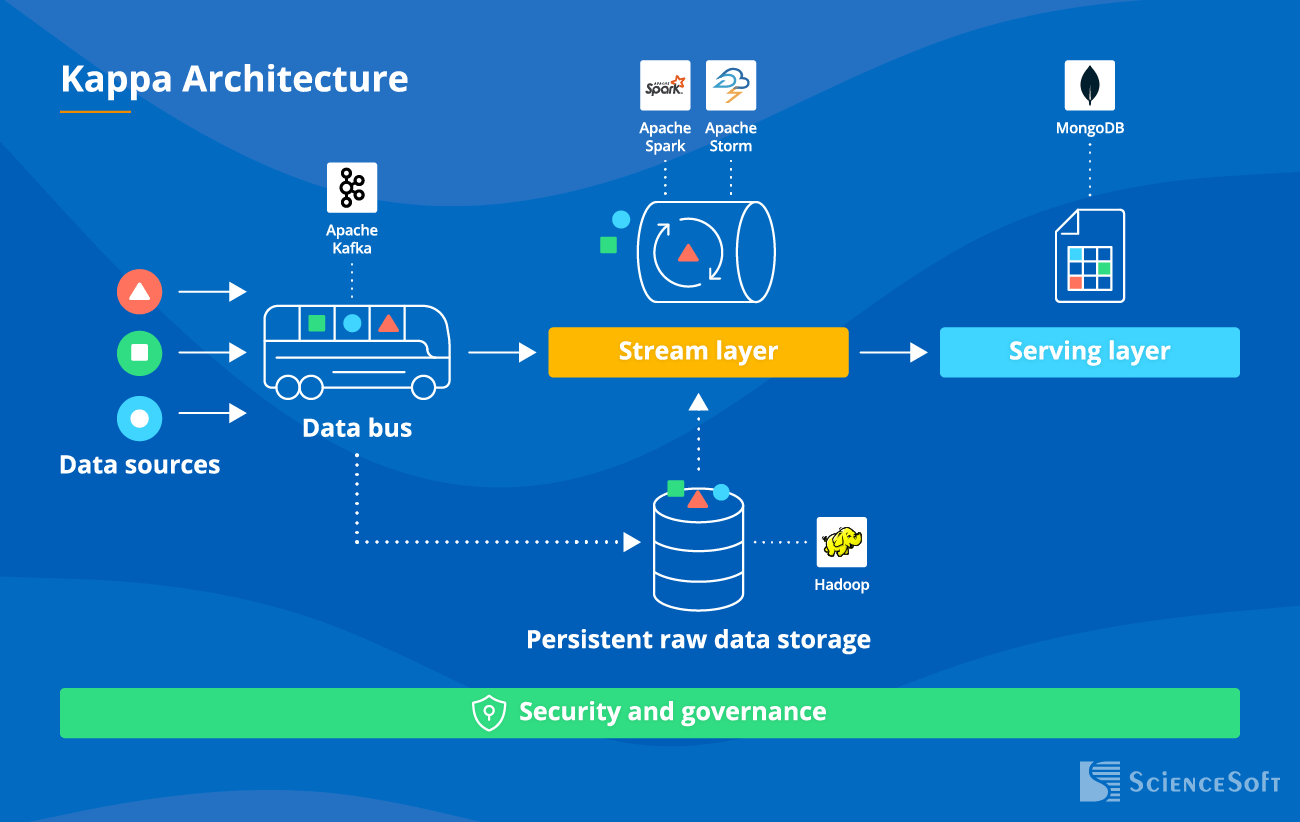
2. Kappa architecture
|
|
|
|
|
|
The essence: In Kappa Architecture, both real-time and batch processing of big data is performed within one data flow (= a single technology stack is used). |
|
|
|
|
|
Pros:
- Easy to test and maintain. Only one set of infrastructure and technology is used.
- Data is easy to migrate and reorganize.
- Easy to add new functionalities and make hotfixes (since only one code base should be updated).
- High data quality with guaranteed data sequence and no mismatches.
- Lower infrastructure cost (storage, network, compute, monitoring, logs) since only one tech stack is used and data needs to be processed only once.
Popular Techs and Tools Used in Big Data Projects
ScienceSoft's teams typically rely on the following techs and tools for big data processing projects:
Data bus / Aggregation layer
- Apache Kafka
- Apache NiFi
- Azure IoT Hub
- AWS IoT Services
- Azure Event Hubs
- RabbitMQ
Stream processing layer
- Apache Kafka
- Apache Spark
- Apache Storm
- Microsoft Fabric
- Amazon Kinesis
- Amazon Managed Streaming for Apache Kafka
- Azure Stream Analytics
- Azure HDInsight
- Azure Synapse Analytics
Data lake
- HDFS
- Microsoft Fabric
- Azure Data Lake
- Azure Blob Storage
- Azure Files
- Amazon S3
Batch processing layer
- MapReduce
- Microsoft Fabric
- Amazon EMR
- Apache Spark
- Apache Hive
- Pig
- Azure HDInsight
- Azure Synapse Analytics
Serving layer / Big data databases
- Apache Cassandra
- Apache HBase
- MongoDB
- Azure Cosmos DB
- Amazon DynamoDB
- Amazon DocumentDB
- Google Cloud Datastore
Serving layer / Data warehouse
- PostgreSQL
- Amazon Redshift
Governance tools
- Apache Airflow
- Talend
- Informatica
- Zaloni
- Apache ZooKeeper
- Azkaban
Security tools
- AWS Cloud Security services
- Azure Security services
Note: Building a big data processing solution is more than just connecting ready components. The share of custom code to integrate different components, support unique operations or create a competitive advantage is still huge and vital.
ScienceSoft: Building Data and Big Data Solutions for 37 Years
- In custom software development since 1989.
- In data management, data analytics and data science since 1989.
- In business intelligence and data warehousing since 2005.
- In big data services since 2013.
- We are proud of our professional and dedicated team of senior project managers, business analysts, solution architects, developers, data analysts, and other IT professionals with 7-20 years of experience.





How ScienceSoft Can Help On Your Big Data Journey
ScienceSoft engineers software solutions that help companies successfully handle the ever-growing amount of data for operational and analytical needs – sensor data, XaaS data, customer and personalization data, images and video, clickstream data, financial transactions data, health data, and more.
With an in-house PMO and mature project management practices, we can handle initiatives of any complexity and drive the project to its goals regardless of time and budget constraints.

Big data consulting
ScienceSoft draws up an effective big data processing strategy, plans high-performance, secure and resilient architecture for your big data app, chooses an optimal technology stack, and proves the viability of a complex big data project with a PoC.

Big data development
ScienceSoft plans, designs, develops, deploys, supports, and evolves organization-wide big data platforms and dedicated big data solutions.
It's High Time to Put Big Data at the Top of Your Agenda
|
|
Big data brings big value. With 62% of mid-size and large companies spending more than $50M on big data, and 12% – over $500M, 92% of them say that their investments in big data are paying off, and they achieve returns. Big data processing and analytics enable more efficient ways of doing business, faster and better decision making, and new successful products and services. |
|
|
The global big data market is huge – it is expected to reach $103B by 2027. |
