Apache Cassandra vs. Hadoop Distributed File System: When Each is Better

Related topics:
Last updated:
Apache Cassandra and Apache Hadoop are members of the same Apache Software Foundation family. We could have contrasted these two frameworks, but that comparison would not be fair because Apache Hadoop is the ecosystem that encompasses several components. As Cassandra is responsible for big data storage, we have chosen its equivalent from the Hadoop’s ecosystem, which is Hadoop Distributed File System (HDFS). Both Cassandra and HDFS enjoy wide adoption among businesses. According to the Cassandra Community report, 41% of the surveyed organizations use Cassandra as their primary database, with 50% of their data being handled by it. Hadoop market (together with HDFS as the framework’s component) also indicates high adoption rates and is projected to reach $1,560 billion by 2033.
Here, we’ll try to find out if Cassandra and HDFS are like twins who are identical in appearance and just bear different names, or they are rather a brother and a sister who may look similar, but still are very different.

Master/Slave Vs. Masterless Architecture
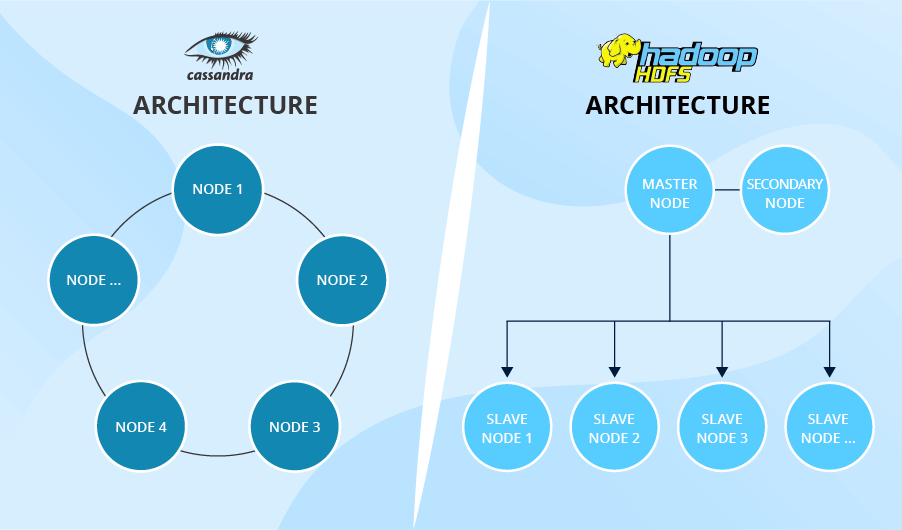
Before we dwell on the features that distinguish HDFS and Cassandra, we should understand the peculiarities of their architectures, as they are the reason for many differences in functionality. If you look at the picture below, you’ll see two contrasting concepts. HDFS’s architecture is hierarchical. It contains a master node, as well as numerous slave nodes. On the contrary, Cassandra’s architecture consists of multiple peer-to-peer nodes and resembles a ring.
5 Key Functional Differences
1. Dealing with massive data sets
Both HDFS and Cassandra are designed to store and process massive data sets. However, you would need to make a choice between these two, depending on the data sets you have to deal with. HDFS is a perfect choice for writing large files to it. HDFS is designed to take one big file, split it into multiple smaller files and distribute them across the nodes. In fact, if you need to read some files from HDFS, the operation is reverse: HDFS has to collect multiple files from different nodes and deliver some result that corresponds to your query. By contrast, Cassandra is the perfect choice for writing and reading multiple small records. Its masterless architecture enables fast writes and reads from any node. High Cassandra performance makes IT solution architects opt for the database if it is required to work with time series data, which is usually the basis for the Internet of Things.
While in theory HDFS and Cassandra look mutually exclusive, in real life they may coexist. If we continue with the IoT big data, we can come up with a scenario where HDFS is used for a data lake. In this case, new readings will be added to Hadoop files (say, there will be a separate file per each sensor). At the same time, a data warehouse may be built on Cassandra.
2. Resisting to failures
Both HDFS and Cassandra are considered reliable and failure resistant. To ensure this, both apply replication. Simply put, when you need to store a data set, HDFS and Cassandra distribute it to some node and create the copies of the data set to store on several other nodes. So, the principle of failure resistance is simple: if some node fails, the data sets that it contained are not irretrievably lost – their copies are still available on other nodes. For example, by default, HDFS will create three copies, though you are free to set any other number of replicas. Just don’t forget that more copies mean more storage space and longer time to perform the operation. Cassandra also allows choosing the required replication parameters.
However, with its masterless architecture, Cassandra is more reliable. If HDFS’s master node and secondary node fail, all the data sets will be lost without the possibility of recovery. Of course, the case is not frequent, but still this can happen.
3. Ensuring data consistency
Data consistency level determines how many nodes should confirm that they have stored a replica so that the whole write operation is considered a success. In case of read operations, data consistency level determines how many nodes should respond before the data is returned to a user.
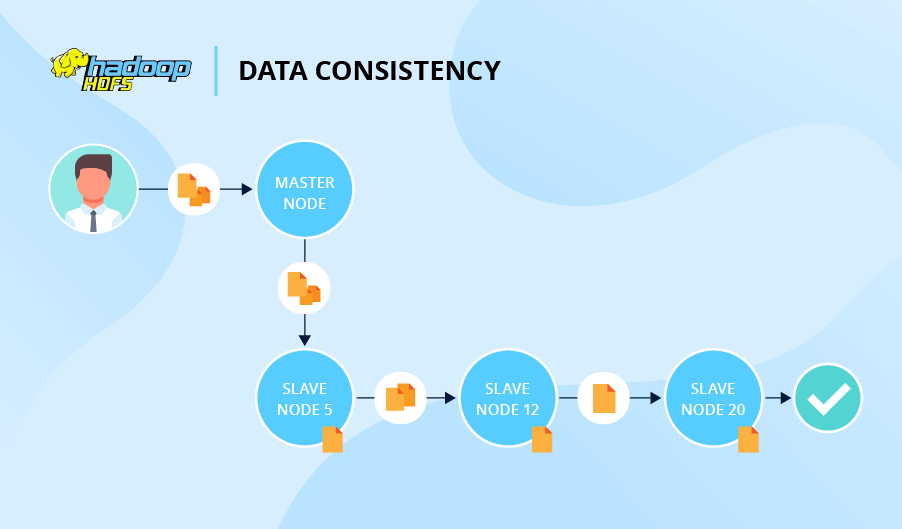
In terms of data consistency, HDFS and Cassandra behave quite differently. Let’s say, you ask HDFS to write a file and create two replicas. In this case, the system will refer to Node 5 first, then Node 5 will ask Node 12 to store a replica and finally Node 12 will ask Node 20 to do the same. Only after that, the write operation is acknowledged.
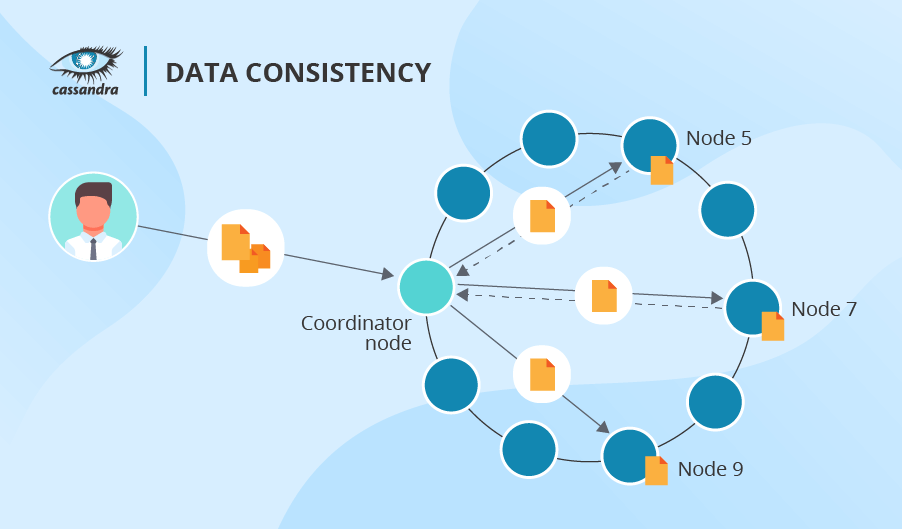
Cassandra does not use HDFS’s sequential approach, so there is no queue. Besides, Cassandra allows you to declare the number of nodes you want to confirm the success of operation (it can range from any node to all nodes responding). One more advantage of Cassandra is that it allows varying data consistency levels for each write and read operation. By the way, if a read operation reveals inconsistency among replicas, Cassandra initiates a read repair to update the inconsistent data.
4. Indexing
As both systems work with enormous data volumes, scanning only a certain part of big data instead of a full scan would increase the system’s speed. Indexing is exactly the feature that allows doing that.
Both Cassandra and HDFS support indexing, but in different ways. While Cassandra has many special techniques to retrieve data faster and even allows creating multiple indexes, HDFS’s capabilities go only to a certain level – to the files the initial data set was split into. However, record-level indexing can be achieved with Apache Hive.
5. Delivering Analytics
Both designed for big data storage, Cassandra and HDFS still have to do with analytics. Not by themselves, but in combination with specialized big data processing frameworks such as Hadoop MapReduce, or Apache Spark.
Apache Hadoop’s ecosystem already includes MapReduce and Apache Hive (a query engine) along with HDFS. As we described above, Apache Hive helps overcome the lack of record-level indexing, which enables to speed up an intensive analysis where the access to records is required. However, if you need Apache Spark’s functionality, you can opt for this framework, as it is also compatible with HDFS.
Cassandra also runs smoothly together with either Hadoop MapReduce or Apache Spark that can run on top of this data storage.
HDFS and Cassandra in the Framework of the CAP Theorem
According to the CAP theorem, a distributed data store can only support two of the following three features:
- Consistency: a guarantee that the data is always up-to-date and synchronized, which means that at any given moment any user will get the same response to their read query, no matter which node returns it.
- Availability: a guarantee that a user will always get a response from the system within a reasonable time.
- Partition tolerance: a guarantee that the system will continue operation even if some of its components are down.
If we look at HDFS and Cassandra from the perspective of the CAP theorem, the former will represent CP and the latter – either AP or CP properties. The presence of consistency in Cassandra’s list can be quite puzzling. But, if needed, your Cassandra specialists may tune the replication factor and data consistency levels for writes and reads. As a result, Cassandra will lose the Availability guarantee, but gain a lot in Consistency. At the same time, there’s no possibility to change the CAP theorem orientation for HDFS.
In a Nutshell
From the description above, it may seem that Cassandra largely outperforms HDFS. Still, if we consider the databases in the context of their respective use cases, we’ll see that both have their optimal uses depending on the data type and its purpose. Below, you can see the comparison of different database parameters and how they make a perfect fit for particular scenarios.
| Parameter | Cassandra | HDFS |
|---|---|---|
| Write latency |
Very low. Writes are distributed across nodes and quickly acknowledged, especially at lower consistency levels. |
Moderate to high. It takes time to coordinate writes via the NameNode and replication. |
| Read latency |
Very low. Cassandra supports random-access reads from any node in the cluster. |
Moderate to high. HDFS needs to reassemble data from multiple nodes for reading. |
| Scalability |
Highly scalable. Masterless architecture allows for adding and removing nodes with minimal disruption. The tech ensures highly configurable replication and consistency. |
Moderately scalable. HDFS relies on a single NameNode, which limits scalability for large clusters. Per-file and directory replication is less flexible than Cassandra’s per-operation settings. |
| Best use cases from a technical perspective |
|
|
| Best use cases from a business perspective |
|
|
You could ask a reasonable question: what if I want to have the best of the two worlds and combine the real-time capabilities of Cassandra with the batch processing power of HDFS? It’s possible! With professional Hadoop and Cassandra consulting, you can choose the optimal technology stack for your case or learn how to benefit from a hybrid approach.
