Alternative Approaches to Implementing Your Data Lake

Related topics:
Last updated:
Is your company determined to implement a data lake for your big data? That’s definitely exciting and great news! However, you have challenging times ahead, as you have so many fundamental issues to clarify and decide upon. At this stage, you are most likely interested in a data lake architecture and the required technology stack. To make your journey smooth and comfortable, our big data consultants have prepared the overview of alternative implementation approaches.
Zones in a data lake
A data lake is a repository intended for storing huge amounts of data in its native format. Data lake implementation will allow you to derive value out of raw data of various types. Unlike a data warehouse, a data lake has no constraints in terms of data type - it can be structured, unstructured, as well as semi-structured. In terms of architecture, a data lake may consist of several zones: a landing zone (also known as a transient zone), a staging zone and an analytics sandbox. Of all the zones mentioned, only staging is the obligatory one, while all the others are optional. To find out what each zone is for, let’s take a closer look at them.
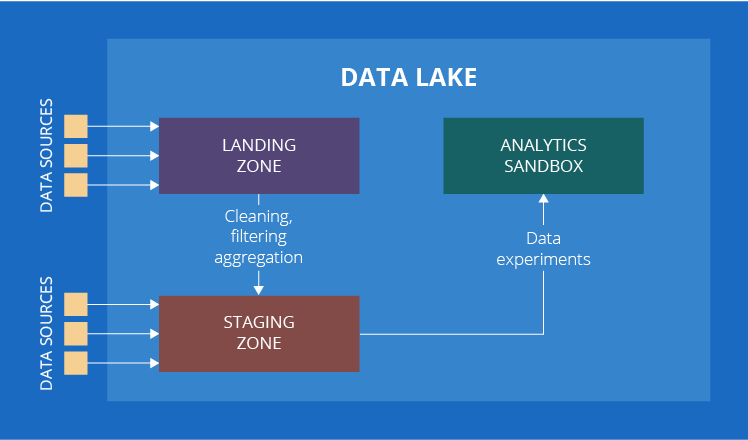
1. Landing zone
Here comes the data (structured, unstructured and semi-structured) that undergoes preliminary cleaning and/or filtering. For example, you collect IoT data from sensors. If one of the sensors is sending abnormally high values while the other sensors that measure the same parameter have not registered anything unusual, a processing engine deployed within this zone will mark the values as erroneous.
2. Staging zone
There are two ways for data to appear in the staging zone. First, it can come from the landing zone (if any), like the sensor data from our previous example. Secondly, we can get data, which does not require any preprocessing, from other internal or external data sources. Customer comments in social networks will be a good example to illustrate this case.
3. Analytics sandbox
This is the zone for data experiments driven by data analysts. It is different from the analytics as we know it, as its findings (if any) are not directly used by business. By the way, we deliberately specified this if any. It happens quite often that analysts apply some models or algorithms to raw data (which may also be coupled with the data from a big data warehouse or from other internal or external data sources) and get no valuable findings. For exploratory data analytics, this is normal.
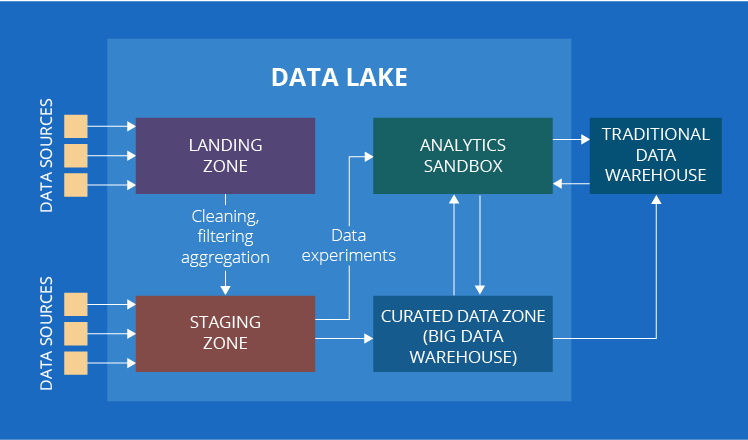
4. And one more zone under question – curated data zone
By now, our list should have been over, if there weren’t one slight hitch. In some sources, you may come upon one more component of a data lake – the curated data zone. This is the zone with organized data ready for data analysis.
There exist different opinions about whether the curated data zone should be considered a part of a data lake or not. While both approaches are reasonable, we think that it should rather not. However, prior to providing the arguments to support our point of view, let’s put the terminology to order.
Have another look at the description of the curated data zone. Doesn’t it look very similar to a good old traditional data warehouse? It absolutely does! The only difference is that a traditional data warehouse deals with traditional data only, while the curated data zone – with both traditional and big data. To neutralize the influence of data types, let’s extend the name to a big data warehouse.
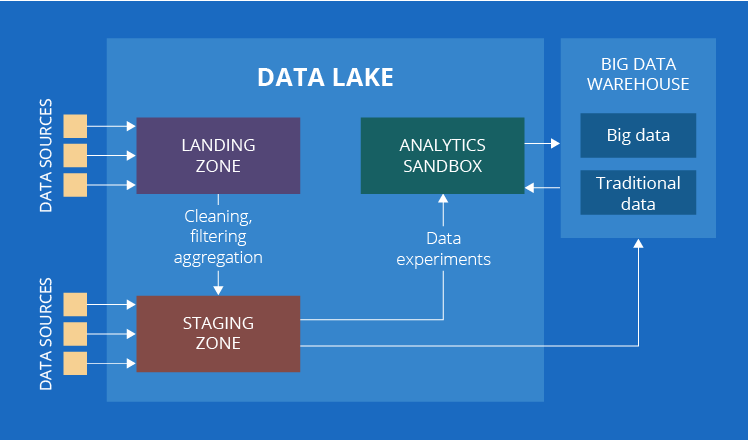
Now, after we clarified that the curated data zone can as well be called a big data warehouse, let’s discuss why we consider that it’s outside a data lake. The data stored in a big data warehouse is fundamentally different from the data in any zone of a data lake – it is more organized, and it is already the source of insights for business users.
Besides, at this stage of data journey, the differentiation between traditional and big data becomes uncritical. Both types peacefully coexist and complement each other to fulfill its purpose – to provide business users with insights. For example, to segment customers, you can analyze a lot of data among which there will be big data such as surfing history on the website and the activities in customer mobile apps. Later you can run reports on sales or profit per customer segment, which is pure traditional business intelligence.
If you wonder why then a big data warehouse is sometimes considered a part of a data lake, we have an explanation for this as well. Most businesses that decide to take the advantage of big data already have a traditional data warehouse in place. So, they usually choose to extend their analytical solution by building a data lake around it. In this case, a traditional data warehouse remains a habitual important element and all new elements are associated with a data lake.
Technological alternatives for implementing a data lake
The list of technologies for big data storage includes a myriad of names: Hadoop Distributed File System, Apache Cassandra, Apache HBase, Amazon S3, MongoDB are just a few most popular ones. Undoubtedly, while selecting a technology stack for a data lake, one will think first of the technologies that enable big data storage. The foundation is the right one, though you need to think about processing as well. So, the list of technologies should be further extended with Apache Storm, Apache Spark, Hadoop MapReduce, etc. No wonder if you are puzzled what combination is the best choice for your data lake!
1. Defining factors to choose a technology stack
Despite each case is individual, we’ve summed up five important factors that will become a starting point of your discussion with your big data consultants:
- Data to be stored and processed: IoT big data, texts, video, etc.
- Required architecture of a data lake
- Scalability
- In-cloud or on-premises solution
- Integration with the existing components of IT architecture.
Is there a leading technology?
According to general big data consulting practice, Hadoop Distributed File System (HDFS) is the most popular among the multitude of possible technologies for a big data lake. The reasons are as follows:
- HDFS is extremely good at handling the diversity of data in a big data lake. IoT big data, video and audio files and text records – with HDFS you can store every data type. If we compare, Apache Cassandra is good for storing IoT big data, while MongoDB – texts.
- HDFS supports a wide range of processing techniques. HDFS is one of the elements of Apache Hadoop ecosystem that includes multiple other components such as Hadoop MapReduce, Hadoop YARN, Apache Hive, Apache HBase, etc. As they belong to the same family, it’s natural that each of them is highly compatible with HDFS. Besides, HDFS has proved to be highly compatible with Apache Spark which gives an opportunity to perform big data processing quickly.
Of course, you can also consider other technologies to implement a data lake. An important criterion is to know how to bypass their limitations. For example, after comparing HDFS and Cassandra, you can decide to run a data lake on the latter. Why not, if you are planning a data lake exclusively as a staging area for IoT data, and you know how to compensate Cassandra’s lack of joins?
2. Data lake as a service
Amazon Web Services, Microsoft Azure, Google Cloud Platform have a relevant offer – a data lake as a service. In fact, it would be difficult for a newbie to spot the differences among these three offers. In essence, they are quite similar: you need an AWS/Azure/GCP account, your data and willingness to pay for the service. In return, you get a predefined set of technologies deployed in the cloud and get rid of a maintenance headache. Under-the-hood technology stack is, of course, different, though the functions they perform are habitual ones: storage, processing, streaming and analytics. We are planning to write a separate blog post revealing the pros and cons of these three offers. So, stay tuned.
Let’s briefly recap
What are the main factors that influence the choice of technologies for a data lake?
- The types of data to be stored and processed
- The zones of a data lake (only a staging zone or a landing zone and an analytics sandbox)
- Scalability
- In-cloud or on-premises solution
- Integration with the existing components of IT architecture.
In the end, should we opt for one technology only?
No, you shouldn’t. Our practice shows that data lake solutions are implemented based on several technologies. To solve a business task, big data consultants can choose a separate technology for each zone of a data lake.
Is there a preferred technology for a data lake?
Hadoop Distributed File System is the most popular, yet not the only technology available. However, be careful and rely on your business goals and, correspondingly, requirements to your future analytical solution rather than on a framework’s popularity.
If I do not want to implement a data lake from scratch, can I opt for a ready-to-use solution?
Yes, you can. Amazon Web Services, Microsoft Azure and Google Cloud Platform offer a data lake as a service. What is needed from you – your data and your subscription and service fees. And you get a data lake that it easy and fast to deploy.
