How to Achieve Vendor Independence in Radiology AI: What to Own, What to Buy, and How to Stay Flexible

Related topics:
6 min read
Last updated:
Editor’s note: In this article, Vadim explains how healthcare organizations can reduce vendor dependence in radiology AI by owning the data, outputs, monitoring evidence, governance processes, and integration layers around their AI tools. This guide is most useful if you already run or plan to run multiple radiology AI tools across sites, need to compare or replace models, support clinical and research AI workflows, or want to keep AI monitoring and model output data under your control.
Vendor lock-in in radiology AI accumulates gradually. You buy algorithms through a PACS marketplace because it is convenient. You use a cloud-native inference service because it is fast. You accept proprietary routing and reporting integrations because nobody wants to delay go-live. Eighteen months later, you have AI in production, but swapping out a weak model, moving clouds, or negotiating with a vendor has become difficult. So, it turns out you haven't really built an AI capability. You have rented one.
However, choosing vendor independence does not mean building everything yourself or rejecting commercial tools and integrated ecosystems. Rather, it means using them through a design that preserves optionality. It means building a system in which models, data, and infrastructure remain separately governable assets; where monitoring is owned internally; and where you can replace an old model with a better one without breaking clinical workflow.
My goal in this article is not to persuade every radiology organization to build a full AI platform. Below, I describe the main layers of vendor independence and show which ones are usually worth addressing first, depending on your AI scale, internal IT maturity, and research ambitions. Radiology groups and specialized hospitals may start with vendor contract terms, data portability, independent validation, and monitoring. Large AMCs and multi-site networks may have stronger reasons to invest in research sandboxes, self-hosted inference, and federated learning. All the recommendations are based on my experience working on similar client initiatives at ScienceSoft.
Start With Data and Output Ownership
The first step toward vendor independence is making sure that imaging data, AI outputs, and workflow evidence do not live only inside a vendor-controlled environment. Most radiology organizations, regardless of size, will benefit from having a proprietary data foundation that allows them to independently route studies, compare models, monitor performance, and replace a vendor without losing operational history.
At a minimum, this data foundation should include:
- Standards-based access to imaging studies through PACS, VNA, or DICOMweb APIs.
- Consistent capture of study metadata needed for routing and monitoring, such as modality, body region, protocol, scanner, site, contrast use, and laterality.
- An organization-owned results database for AI outputs. This database should store outputs in a consistent format across vendors and record which model version processed each study, what result or score was returned, which threshold triggered an alert, and how the radiologist acted on that alert. Without this layer, a vendor-owned dashboard may become your only source of truth about AI performance, making future model comparison, renegotiation, or replacement much harder.
The same foundation should also support controlled data exchange with external AI vendors. Every outbound study, returned result, routing decision, and threshold change should be logged. If data leaves the institutional environment, de-identification and re-identification rules should be governed internally, not left to ad hoc project decisions. For clinical validation and monitoring, the organization should also have a way to locally capture radiologist feedback, corrections, and adjudicated cases. These capabilities are useful even if all AI models are commercial because they let the provider evaluate AI behavior on its own data and preserve evidence across vendor changes.
Add Validation, Monitoring, and Governance
Deploying any AI model to production is the beginning of an ongoing operational responsibility. Unlike traditional software, AI models can degrade silently when the distribution of input data shifts relative to the training distribution. A scanner upgrade, a new contrast protocol, or an epidemiological change in the patient population can cause a model's performance to fall below its validated baseline without generating any error messages. This is why MLOps — Machine Learning Operations, or the processes and tools used to validate, monitor, update, and retire AI models — is not merely good practice in radiology AI, but a clinical safety requirement.
In my experience, some healthcare leaders believe they only need MLOps if they train their own models. But even if all your AI tools are commercial, you still need a controlled process for accepting new models, establishing local performance baselines, monitoring behavior, reviewing vendor updates, and retiring or replacing underperforming models. For models that were already in production before you established MLOps, the same process starts with reconstructing the baseline: which version is running, what data it was validated on, what thresholds are used, and how its outputs affect clinical workflow.
Ultimately, the goal is to own the evidence base around every deployed model. At a minimum, the organization should track a focused set of operational metrics that connect model performance to workflow value and safety:
- Local performance: sensitivity, specificity, positive predictive value, or measurement accuracy, depending on the model’s task and your patient population.
- Alert burden and actionability: how often alerts are dismissed, corrected, ignored, or followed by a clinically meaningful action.
- Time-to-read delta: whether reading becomes faster with AI than without it.
The first version of this KPI dashboard can be built quickly in Power BI or Tableau using structured exports from PACS, RIS, and the monitoring layer.
Statistical monitoring should also detect distribution shifts, even when the institution lacks access to model weights. In practice, this means comparing current input data statistics, such as HU histograms, slice-count distributions, protocol mix, and scanner-manufacturer mix, against the baseline recorded at deployment. A material shift does not automatically prove model failure, but it should trigger clinical reassessment.
This monitoring baseline is one of the most important distinctions between an AI pilot and an AI capability: a pilot proves that a model can run; a capability means the organization can monitor, compare, update, and retire models safely.
I also strongly recommend creating a Clinical AI Governance Committee rather than leaving model governance solely to IT. The chair should usually be the Chief Radiologist or Chief Medical Information Officer, with standing participation from radiology informatics, IT and infrastructure, quality and patient safety, and legal and compliance. You might also benefit from a patient representative. This committee will:
- Approve each new AI model (and reassess already deployed models after major vendor updates or workflow changes) using a model approval checklist.
- Conduct regular performance reviews for every deployed model.
- Oversee incident management in case AI makes a clinically significant mistake.
- Own threshold policy for worklist triage and define who can change confidence thresholds, how, and with what audit trail.
- Decide when a model should remain in production, return to shadow mode, be rolled back, or be retired.
Secure and Audit the Platform
Radiology AI systems handle some of the most sensitive patient data in a health system, and large AMCs or radiology groups often add another layer of complexity because they operate across multiple sites, research environments, and affiliated clouds. DICOM studies can expose protected health information through metadata, burned-in annotations, linked reports, order context, and clinically sensitive findings. That is why the security architecture of an AI platform must balance this sensitivity with operational practicality for radiology workflows.
The defense-in-depth security model I propose applies independent controls at every layer of the stack.
- At the network perimeter, WAF (Web Application Firewall), DDoS mitigation, and zero-trust network access (ZTNA) can reduce reliance on broad VPN access rather than simply extending legacy perimeter models.
- The application layer enforces OAuth 2.0 / OIDC authentication, role-based access control for clinical users, administrators, service accounts, and research users, and mutual TLS between internal services.
- At the data layer, PHI must be encrypted at rest (at least AES-256) and in transit (at least TLS 1.2+ or TLS 1.3), with key management handled by a dedicated secrets service (HashiCorp Vault, AWS KMS, or Azure Key Vault) rather than application code.
- The de-identification pipeline must be validated against DICOM PS 3.15 Attribute Confidentiality Profiles and include checks for burned-in pixel PHI, recognizable visual features, private tags, and re-identification risks before studies are used for research or sent outside the institutional environment. DICOM itself notes that Attribute Confidentiality Profiles do not guarantee removal of all identifying information and should be part of a broader de-identification process.
- Just as importantly, every routing decision, result handoff, alert, and threshold change should be logged for auditability, because vendor independence is only defensible if the institution can explain what happened and why. Audit design should also define log retention periods, break-glass access procedures, and incident response ownership, so emergency access and AI-related errors are traceable rather than handled informally.
And then, obviously, compliance is essential. But the obligations depend on deployment geography, model type, vendor role, and the organization’s role in the AI lifecycle. A hospital deploying a cleared commercial AI tool has different responsibilities from a company developing or materially modifying an AI-enabled medical device. Depending on the case, radiology AI programs may need to address HIPAA, FDA 21 CFR Part 11, FDA SaMD guidance, GDPR, EU MDR, the EU AI Act, or other regional legal frameworks.
As for vendor independence when it comes to compliance, the basic discipline is to document three boundaries: where PHI leaves the institution, where the regulated clinical algorithm begins and ends, and where institution-owned workflow software takes over. Vendor contracts should also cover BAAs or DPAs, subcontractor disclosure, data residency, retention and deletion rules, permitted secondary use of data, breach notification, and access to security and audit evidence. This is especially important when the same organization supports both production and research pipelines.
Add Orchestration When the AI Program Becomes Too Complex to Manage Vendor by Vendor
After you have control over imaging data, AI outputs, validation evidence, monitoring, and audit logs, the next question is whether your organization needs an orchestration layer. This layer becomes useful when you run several AI tools across sites, compare vendors for the same clinical task, use both vendor-hosted and internally hosted models, or need consistent routing and monitoring rules across the AI portfolio.
In a simple deployment, a PACS, RIS, or worklist may connect directly to one commercial AI tool. That can be enough at the early stage. As the AI program grows, direct point-to-point integrations become harder to govern. Each vendor may have its own routing logic, result format, dashboard, update cycle, and uptime dependencies. Replacing any model then requires changes in integration, workflow, monitoring, and user training.
An orchestration layer solves this by sitting between clinical systems and AI tools. It decides which studies go to which approved model, sends the required data, receives the result, records what happened, and routes the output back to the right clinical workflow. Instead of letting every model vendor define its own path into the clinical workflow, your organization defines common rules and sets them up in the orchestrator:
- Which studies are eligible for AI processing.
- Which model receives which type of study.
- What metadata is sent with the image.
- Whether de-identification or pseudonymization is required.
- Where the result is stored.
- Which workflow receives the result: worklist, report, alert, dashboard, or quality review.
- How errors, delays, and unavailable vendor endpoints are handled.
This is where vendor independence becomes operational. If two models perform the same clinical task, the organization can compare them using the same routing, monitoring, and results-capture logic. If one model is replaced, the surrounding clinical workflow does not need to be rebuilt from scratch.
Keep a model registry as a source of truth
A model registry is an internal catalog of AI models approved, tested, or retired by the organization. By implementing a model registry on MLflow, DVC, or a compatible alternative, you can maintain a complete lineage of every AI model in your system.
The orchestration layer can then consult the registry to determine which model is approved for a given modality, body region, clinical task, site, and workflow state, and automatically route the requests from connected systems (e.g., a PACS workstation, a mobile alert application, a reporting tool) to the right model. The registry also becomes the main source of truth for clinical governance, regulatory audit, and model comparison.
- For commercial models, the registry typically does not need training data lineage or model architecture details that the vendor does not disclose. It should store the information your organization can govern: version, configuration, regulatory references, local validation results, threshold settings, known limitations, deployment status, and retirement history.
- For internally developed or self-hosted models, the registry can hold more technical information: framework, architecture, training data version, experiment lineage, container version, and internal test results.
Use an external model gateway for commercial AI tools
Most FDA-cleared commercial models will remain vendor-hosted or distributed as controlled containers with license enforcement mechanisms that prevent weight extraction or redeployment outside the vendor's infrastructure. An external model gateway (a secure API proxy layer) helps integrate these tools without giving each vendor a direct, uncontrolled path into the patient data environment.
The gateway can handle vendor authentication, rate limits, usage metering, data minimization, de-identification where appropriate, results intake, SLA monitoring, and error logging. It also creates a clean technical and contractual boundary: you can see which data was sent, which result came back, how long processing took, and whether the vendor met agreed service levels.
The gateway should also define fallback behavior. If a vendor endpoint is unavailable, the system should trigger a governed fallback workflow. Depending on clinical risk, this may mean sending the study through standard radiologist review, notifying operations teams, pausing AI-assisted prioritization, or using a preapproved alternative model.
Add an internal inference layer when it becomes necessary for self-hosted models
Some organizations will also need an internal inference layer for self-hosted models. This becomes relevant when the AI portfolio includes internally developed models, open-source models, models that must run inside the institutional environment, or commercial containers deployed on the organization’s infrastructure. In practice, this is usually the case for large academic medical centers, multi-site health systems, and mature radiology groups that run several AI models, need stricter control over data residency, or want to standardize model serving across vendors and internal teams.
In that case, tools such as NVIDIA Triton Inference Server can help serve models built in different frameworks through a common infrastructure. Triton supports several major deep learning frameworks (TensorFlow, PyTorch, ONNX, TensorRT), enabling the health system to run heterogeneous models (different frameworks, vendors, and hardware targets) without building a separate serving path for each framework or vendor-supported runtime.
Triton’s dynamic batching and concurrent model execution capabilities can improve throughput and GPU resource utilization when configured to the organization’s workload and latency requirements. This is useful in radiology AI programs where individual model requests may be sporadic, but aggregate demand across multiple models, sites, and reading hours can still justify shared GPU infrastructure. Kubernetes, GPU operators, and workflow engines such as Argo Workflows or Apache Airflow can also be useful when the organization needs scalable deployment, GPU resource management, and repeatable multi-step AI workflows.
Add Advanced Research Capabilities Selectively
The four stages/layers described above help organizations stop being operationally dependent on AI vendors. The fifth layer is optional. It is for organizations that want to go further: use their own imaging data and clinical expertise to generate independent evidence, improve models, or create their own AI assets.
This layer is most relevant for:
- Academic medical centers with AI research programs.
- Multi-site health systems that have enough data diversity to test or improve models.
- Specialized hospitals with rare, complex, or protocol-specific cases not well served by commercial AI.
The foundation of this layer is a separated research environment that can receive de-identified or pseudonymized copies of studies without affecting live clinical workflow. This research sandbox should be isolated from the production AI environment, governed by access controls, and supported by dataset versioning, annotation tools, and audit logs. Its purpose is to let the organization evaluate MONAI bundles, vendor proofs of concept, emerging foundation models, and internally developed algorithms on local data while keeping clinical operations stable and protected.
Federated learning deserves special attention in multi-site networks, academic collaborations, referral networks, and regional data collaboratives. It is not a starting point for most radiology AI programs. It becomes relevant when several sites have sufficient data, legal alignment, technical maturity, and research capacity to train or improve models together. In this setup, each site trains the shared model locally on its private dataset and sends model updates, rather than raw patient data, to an aggregation service. Each participant then benefits from the improved global model without surrendering local imaging data. NVIDIA’s MONAI Federated Client is one practical example of this approach, and multi-institutional imaging initiatives such as the FeTS brain tumor segmentation challenge have shown that federated learning is already feasible in medical imaging research.
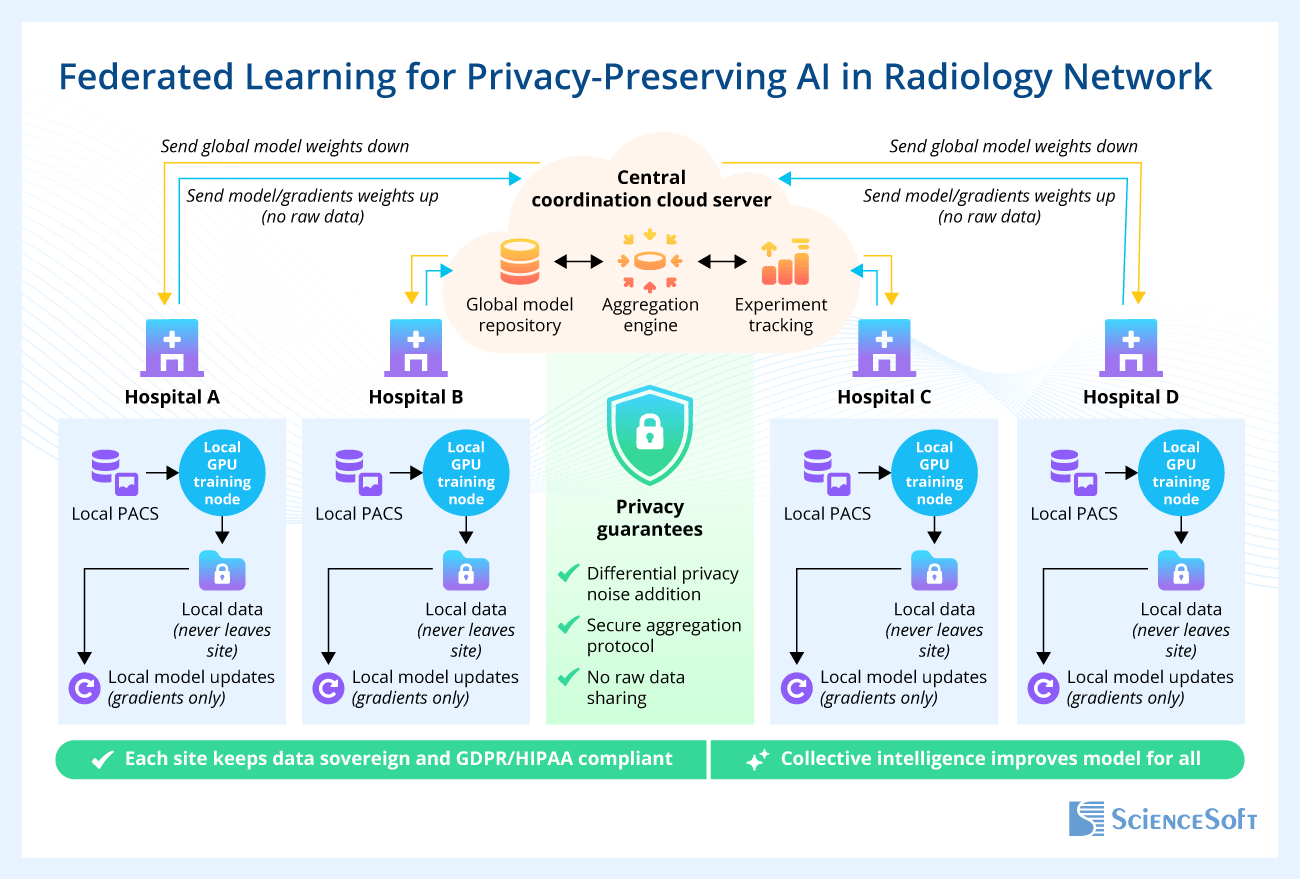
The same governance principles that apply to commercial models should also apply to internally developed models. Research teams should store model artifacts, dataset versions, evaluation results, intended use, known limitations, approval history, and retirement decisions in a governed registry. Otherwise, internal development can create another form of lock-in: undocumented models, unclear training data lineage, or research code that cannot be validated, reproduced, or safely transferred into another environment.
Promoting a research model into clinical production is a separate decision, not a natural next step. It may require additional clinical validation, regulatory review, cybersecurity assessment, integration testing, and a clear definition of whether the model qualifies as software as a medical device. For that reason, advanced research capabilities should be treated as a selective extension of vendor independence, not as a requirement for every radiology AI program.
Design Principles That Prevent Vendor Lock-In
Regardless of how far you want to take vendor independence, keep in mind the following general design principles. Applied consistently, they will reduce the chance that any single vendor will gain structural leverage over your AI program:
- Use open standards such as DICOM, HL7/FHIR, DICOMweb, and ONNX where possible. Avoid proprietary data formats or inter-component APIs that cannot be reimplemented independently.
- Separate storage from compute so that imaging data, AI outputs, model artifacts (where available), and serving infrastructure are independently replaceable.
- Contract explicitly for data portability so that you can export AI outputs, logs, annotations, configuration data, validation evidence, and other model-related records in standard formats within an agreed period (e.g., 30 days of contract termination).
- Keep the platform multi-cloud ready through infrastructure-as-code. This preserves the ability to migrate between cloud providers as pricing and capability evolve.
- Run regular comparative evaluation so that new models can be benchmarked against existing ones.
Conclusion
I believe that artificial intelligence may prove as transformative for diagnostic radiology as the invention of cross-sectional imaging. But the organizations that gain the most from it will not necessarily be those that deploy the most algorithms first or sign contracts with the most prominent vendors. They will be the ones who build the governance, data architecture, and technical platform to own AI as a capability rather than consume it as a string of disconnected tools.
