Inventory Optimization Software
Key Features, Implementation Options, Costs
In inventory software development since 2012 and in data analytics and AI since 1989, ScienceSoft helps companies design and build effective analytics-driven inventory optimization solutions.

Contributors

Digital Supply Chain & AI Consultant and Business Analyst, ScienceSoft

Principal Architect, AI & Data Management Expert, ScienceSoft
Inventory Optimization With Data Science: The Essence
Inventory optimization is aimed to help companies avoid stockouts and overstocking and minimize inventory holding and shortage costs. Multi-echelon inventory optimization software serves to define the proper inventory levels across storage and selling locations and control real-time stock.
Inventory optimization solutions powered with data science rely on artificial intelligence (AI) and machine learning (ML) techniques, including deep learning. They offer analytics-based inventory planning and calculation of optimal safety stock and replenishment time for each product item.
- Suitability: complex multi-echelon distribution networks, perishable inventory, seasonal goods.
- Necessary integrations: an inventory management system, CRM, ERP, procurement software, pricing software, etc.
- Implementation time: 7–13 months for custom inventory optimization software.
- Development costs: $100,000–$600,000+, depending on the solution’s complexity. Use our online calculator to estimate the cost for your case.
- ROI: Up to 300%.
Data Science Models Used in Inventory Optimization Software
A data science model used for inventory analytics is a backbone of inventory optimization software. There are several main types of analytical models that differ in efficiency, cost, and the required degree of human involvement in model creation and management. We thoroughly weigh their benefits and limitations for each customer to choose the one that fits the client's specific needs best.
A statistical model
Capabilities: calculating an optimal inventory level based on the forecasted demand, known probability distribution of demand, standard deviation of demand, inventory purchasing and selling prices.
Key benefits: prompt model implementation, cost-effective optimization of inventory items with well-known and stable demand.
Limitations: suboptimal efficiency in real life due to the highly uncertain and constantly changing demand probability distribution, large degree of human involvement is needed to prepare the input data and control model performance.
A non-neural network (non-NN) machine learning model
Capabilities: revealing complex inventory demand patterns based on the analysis of diverse internal and external demand drivers, calculating optimal inventory levels with a view to inventory holding and shortage costs.
Key benefits: fast model design and setup, high prediction accuracy.
Limitations: efficient model performance requires accurate manual cleansing and structuring of input data and ongoing human participation in model management.
An ML-based model with a deep neural network (DNN) at its core
Capabilities: skipping the demand forecasting stage and optimizing inventory directly, capturing and analyzing complex non-linear dependencies between diverse inventory demand and cost factors.
Key benefits: smooth accommodation of inventory big data, prompt, highly precise, and purely algorithm-driven suggestions on optimal inventory levels, minimal human intervention required to operate the model.
Limitations: model implementation and fine-tuning require the involvement of data scientists and software developers.
ScienceSoft’s data scientists consider DNN approach the most effective for solving inventory optimization tasks.
A Sample Architecture of DNN for Inventory Optimization by ScienceSoft

DNN is formed by numerous layers that consist of neurons (or ‘nodes’). The neurons of one layer are connected to the neurons of the layer that follows. At each layer, certain coefficients (or ‘weights’) are applied to the values produced by the neurons of the previous layer. A single neuron can identify multiple linear or non-linear dependencies, while several neurons can identify more complex dependencies, such as exponential growth or decline, surges and temporary falls, etc. Depending on the complexity of dependencies, DNN may require 3-10+ hidden layers and from 50 to 200,000+ weights for efficient inventory optimization.
DNN treats historical sales data by inventory item, selling channel, region, etc., as inputs. Then, the network assigns random weights and comes up with an output, which is the optimal inventory level. At the model training stage, the network then applies a loss function that calculates the difference between this output with the one from the data set used for training. Besides, the loss function weighs holding and shortage costs to balance the risks of stockouts and overstocking. As long as the optimal balance between holding and shortage costs isn’t found, DNN keeps reassigning the weights to minimize the error. When the weights are fine-tuned, the DNN is ready to generate real-life forecasts.
Hide
Inventory Optimization Software: Key Features
ScienceSoft creates inventory optimization solutions with unique functionality closely bound to our clients’ business objectives. Here, we list the features commonly requested by our clients:
![]()
Inventory optimization model management
- Creating statistical and AI inventory optimization models with configurable numerical and categorical input parameters, rules for data normalization and encoding, etc. (for data scientists).
- Automated recalculation of an inventory optimization model’s outputs as new relevant data appears.
- Real-time monitoring of inventory optimization model variance.
- Alerts to data scientists on abnormal (poor/superior) model performance.
- Continuous model self-tuning, including automated backpropagation of model errors and weights adjustment (for DNNs).
![]()
Demand analysis
- Time series analysis to compare historical demand data across user-defined periods and identify demand trends.
- Multi-dimensional sensitivity analysis to assess the impact of particular variables (product price, season, etc.) on demand changes and identify key internal and external demand drivers.
- Analyzing the impact of non-recurring historical events (e.g., product promotions, new product introduction) on demand to identify historical demand data exceptions not to consider when calculating optimal inventory levels.
![]()
Inventory-related data analysis
Analyzing available historical and real-time data that may influence inventory optimization decisions:
- Manufacturing and sales data.
- Demand seasonality.
- Pricing data.
- Product promotions.
- Inventory lead time.
- Inventory holding and shortage costs.
- Customer commitments and service levels.
- Case-specific high-level types of data (e.g., weather forecast for weather-sensitive items), and more.
![]()
Prescriptive analytics on inventory replenishment
- AI-based recommendations on:
- Optimal purchasing time for each inventory item.
- Optimal time of inventory reallocation between different manufacturing facilities, warehouses, distribution centers, trading partner locations, points of sale, etc. (for multi-echelon inventory optimization).
- Alerts on inventory items that require replenishment (triggered by reorder points).
![]()
Inventory costs analysis
- Cost-benefit analysis to compare possible combinations of inventory holding and shortage costs for different safety stock amounts.
- Inventory cost optimization suggestions.
- Applying a loss function to automatically weigh and balance inventory holding and shortage costs (for DNNs).
- Automated calculation and analysis of savings with inventory optimization.
![]()
Inventory optimization insights visualization
- Support for various types of inventory predictions visualization:
- Drill-down dashboards with customizable charts, graphs, tables, interactive maps, and more.
- Advanced data visualization techniques, such as three-dimensional scatter plots and graphs.
- Scheduled and ad hoc reporting of inventory optimization in supply chain.
- Customizable inventory report templates for different user roles.
Industry-specific inventory optimization features
In addition to general-purpose functionality, we can introduce specific features to enhance inventory optimization workflows for your particular industry.
![]()
Retail inventory optimization
AI-based shelf planogram analysis and inventory placement optimization in retail stores.
![]()
Ecommerce inventory optimization
Analytics-based calculation of optimal stock levels across fulfillment locations; alerts on required item transfers.
![]()
Healthcare inventory optimization
Defining safety stock and reorder points for perishable medical products; tracking medical inventory utilization compliance.
![]()
Manufacturing inventory optimization
Bill of materials (BOM) analysis and inventory allocation optimization for goods in production.
Key Integrations for Inventory Optimization Software
ScienceSoft suggests setting up the following integrations to enable fast and efficient aggregation of data on diverse factors that influence inventory levels and ensure seamless flow of analytical results to the relevant systems:
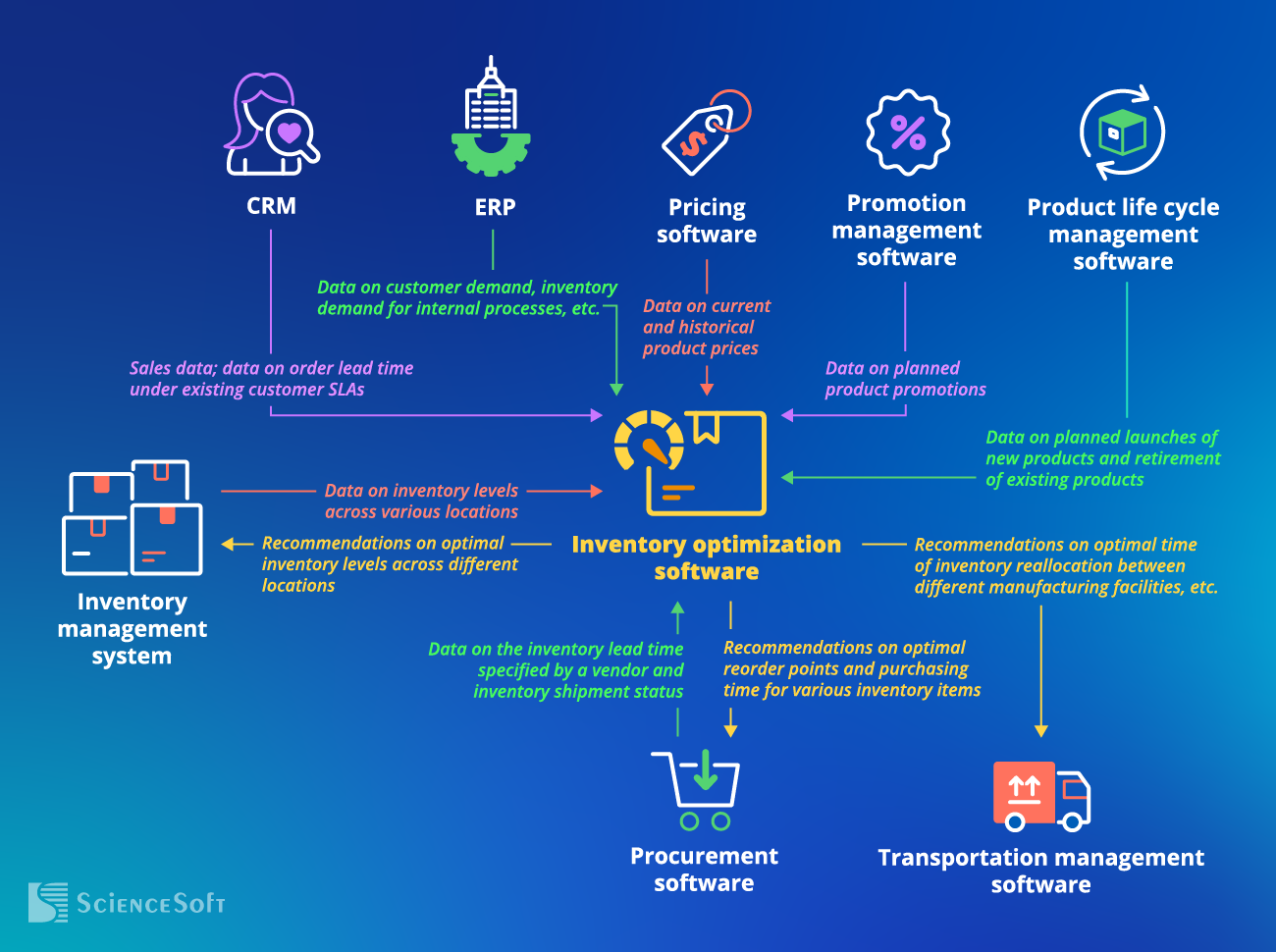
Essential data sources
- Inventory management system – to analyze inventory levels across various locations, generate recommendations on optimal safety stock and reorder points.
- CRM – for the demand analysis and data-driven calculation of optimal inventory levels. Alternatively to CRM, the inventory optimization solution can integrate with an order management system or directly with selling channels (e.g., a company’s ecommerce website, a point-of-sale system, or a third-party ecommerce marketplace).
- ERP – for accurate multi-location inventory planning; to plan optimal time for inventory reallocation from warehouses to the locations where operations are conducted.
- Procurement software – to calculate optimal inventory reorder points and plan safety stock across locations.
- Pricing software – to analyze price elasticity of demand and model optimal inventory levels for different prices.
- Promotion management software – to optimize inventory with a view to planned product promotions.
- Product life cycle management software – to consider the impact of a new product launch on customer demand changes across the existing product portfolio when planning inventory.
Key systems that leverage inventory analytics
- Inventory management system – for data-driven inventory planning and multi-echelon inventory optimization.
- Procurement software – for accurate inventory procurement planning and timely inventory replenishment.
- Transportation management software – to accurately plan inter-facility inventory shipment.
ROI Factors for Inventory Optimization Software
Based on the practical experience engineering custom inventory solutions and implementing data analytics, ScienceSoft’s consultants have defined important factors that help maximize the value of technology for inventory optimization processes.
- The use of the maximum of data sources, including back-office systems, social media, competitors’ websites, weather forecasting portals, and more to plan safety stock taking into consideration all available internal and external demand factors.
- Intelligent identification of unusual and erroneous observations in historical demand data not to consider when calculating optimal inventory levels and stock KPIs.
- Involving professional data scientists to design inventory optimization models and tune them at the model training stage to ensure employing proper models for various inventory categories, accurately identifying demand drivers, applying a proper approach to avoid model overfitting, etc.
Steps to Develop a Robust Inventory Optimization Solution
At ScienceSoft, inventory optimization software development typically involves the following steps:
1.
Requirements gathering

- Analyzing the customer’s inventory-related workflows and inventory optimization needs.
- Defining the required inventory aspects to optimize: e.g., multi-echelon inventory levels, reorder points, replenishment schedules and amounts.
- Determining inventory data sources and downstream software systems that need to ingest analytics results.
2.
Software design

- Composing a detailed feature set for the inventory optimization solution.
- Deciding on the best-fitting data science models (or their combination) to use for inventory optimization.
- Creating a software architecture based on the customer’s unique requirements for scalability, availability, performance, and inventory data protection.
- Designing user-friendly dashboards to overview the inventory KPIs and prescribed inventory optimization steps.
3.
Analytical model design

- Selecting the proper input parameters for the inventory optimization model (stock data, carrying costs, lead time, and more).
- Designing custom rules for optimization logic, e.g., to consider the customer’s preferred inventory supply strategy (JIT, JIS, MRP, etc.) when calculating the optimal reorder points.
- (for ML models) Composing an appropriate training dataset for the optimization model.
A well-thought-out tech stack helps significantly reduce the cost of inventory optimization software. We use proven frameworks, OOTB building blocks for the model logic, ready-made UI components, and open-source APIs where possible to speed up development and optimize the team’s efforts.


4.
Implementation

- Developing the back end and front end for inventory optimization software.
- (for ML-powered systems) Inventory optimization model development, training, and tuning.
- Setting up scalable storage for analytical results, implementing inventory data encryption and role-based access control mechanisms.
- Inventory optimization software integration with the required systems to automate inventory data input and output of analytical results.
- Solution deployment in the production environment.
Optional:
- Employee training on how to optimize inventory with the new solution.
- Continuous support and evolution of inventory optimization software (covers data science model maintenance).
For more information on the specifics and timelines of each stage, please visit our detailed guide to inventory software development.
Inventory Optimization Software Implementation Costs and Financial Outcomes
The cost of inventory optimization software implementation varies greatly depending on:
- The number and complexity of a solution’s functional modules.
- The implementation of data science and AI technologies.
- The amount and complexity of inventory-related data used for analytics.
- The number and complexity of integrations (with an inventory management system, ERP, CRM, procurement software, etc.).
- The number of software users, their roles and specific needs.
- Software performance, security, latent capacity and scalability requirements, and more.

From ScienceSoft’s practice, a custom inventory optimization solution of average complexity may cost around $200,000–$350,000.
The cost to develop comprehensive inventory optimization software for a large enterprise may exceed $600,000.
Want to know the cost of your inventory optimization solution?
Key Benefits of Inventory Optimization With Data Science
Inventory optimization software can bring up to 300% ROI.
Off-the-Shelf Inventory Optimization Tools: ScienceSoft’s Recommendations
Oracle Fusion Cloud Inventory Management
Description
- Calculating optimized inventory levels (by item, location, region, etc.) based on the analysis of customer demand data, seasonality, promotional events, particular product attributes, etc.
- AI recommendations on time-phased replenishment quantities for each inventory item and optimal time for inventory transfer between various storage locations.
- Monitoring the performance of the inventory optimization model, analyzing root causes of inventory planning errors.
Cautions: requires integration with Oracle Cloud
Best for
Supply chain inventory optimization in complex supply networks.

Blue Yonder Inventory Management
Description
- AI-powered inventory planning.
- Analytics-driven multi-echelon inventory optimization.
- Automated safety stock calculation by inventory item and location.
- Recommendations on the replenishment strategy and internal movements for each inventory segment based on the analysis of inventory lead time and localized customer demand.
Cautions: costly and effort-consuming integration with legacy back-office systems.
Best for
Stock optimization in omnichannel retail.
Microsoft Dynamics 365 Supply Chain Management (Inventory Management module)
Description
- AI-based forecasting of demand and stock levels across locations.
- Calculating optimal inventory levels for raw materials and finished goods based on the analysis of historical sales, purchasing, supply chain data.
- Automated calculation of optimal reorder points for each SKU.
- Native integration with Microsoft Power BI for advanced visualization of inventory analytics.
Cautions: substantial customization efforts to meet unique inventory optimization needs.
Best for
Inventory optimization in manufacturing.
When to Opt for a Custom Inventory Optimization Solution
ScienceSoft recommends choosing custom development in the following cases:
- You need an inventory optimization solution providing specific functionality, for example, calculating safety stock for perishable, weather-sensitive, or highly regulated (e.g., medicines) inventory with a view to case-specific demand drivers and cost factors.
- You want to integrate stock optimization software with your legacy corporate systems smoothly and cost-effectively.
- You have large teams involved in inventory optimization tasks and want to avoid costly subscription for market-available inventory optimization tools.
- You want to implement core functionality first and evolve your inventory management system with data science technologies for inventory optimization over time.
Implement Inventory Optimization Software With ScienceSoft
In supply chain IT since 2012 and in data science and AI engineering since 1989, ScienceSoft helps companies design and build data-driven inventory optimization solutions.

Inventory optimization consulting
- Analysis of your inventory optimization needs.
- Suggesting optimal approaches to inventory optimization, inventory optimization solution features (including those powered by data science technology), practical architecture, and technology stack.
- Preparing a plan of integrations with inventory management software, ERP, CRM, procurement software, etc.
- Implementation cost & time estimates, expected ROI calculation.

Inventory optimization software development
- Inventory optimization needs analysis.
- Solution conceptualization.
- Architecture design.
- Inventory optimization software development.
- Integrating the solution with the necessary corporate systems.
- Quality assurance.
- User training.
- Continuous support and evolution (if required).
About ScienceSoft
ScienceSoft is a global IT consulting and software development company headquartered in McKinney, Texas. We help companies design and build reliable data science solutions for analytics-driven inventory optimization. In our projects, we employ robust quality management and data security management systems backed up by ISO 9001 and ISO 27001 certificates.
