Microservices Architecture Explained with a Java Example: When a Monolith Doesn’t Work

Related topics:
8 min read
Last updated:
Editor’s note: After successful implementations by such big players as Google, Netflix, Amazon, and eBay, the microservices approach to architecture stirred up an amazing hype. In the article, Ulad takes ScienceSoft’s real Java-based project as an example and shows how it unfolds, from an architectural decision to the choice of techs. If you feel you need help with Java application design or re-design, you’re welcome to consider our offering.
In ScienceSoft’s practice, we often resort to microservices when developing large and complex web applications, especially cloud-based ones. Still, at the beginning of cooperation, some of our clients ask: ‘Why should we abandon an old and trusted monolith for more costly, effort-intensive, time-consuming development?’ And they’re right. Microservices-based development is much more demanding and resource-intensive, but with the benefits, a business can achieve, it can be completely worth it.
In this article, I’d like to help you understand the essence and value of microservices, using as an example of the work we did with the Java team at ScienceSoft. We’ll consider both architectural approaches, and I’ll tell you how the decision in favor of microservices was made.

A quick update on monolith and microservices
Let me quickly remind you of the essence of both architectural styles. A monolithic architecture keeps it all simple. An app has just one server and one database. The program consistently implements all business logic step by step, moving to the next stage only after the previous one is completed. All the connections between units are inside-code calls.
The microservices architecture is a particular case of a service-oriented architecture (SOA). SOA is a software design style where independently deployable modules interact with each other via communication protocol over the network. What sets microservices apart is the extent to which these modules are coupled. Microservices are more independent and tend to share as little elements as possible. Each server is atomic by nature and performs one certain business function.
A case of microservices implementation
Simply put, one of our clients needed a custom mobile retail application. The application had to log a user into their profile, take their order, and send email notifications (order confirmation, shipping updates, etc.). The innovative and very promising start-up initiative had already received very positive feedback from the business community. After first prototypes were released, several large companies were willing to introduce the application into their workflows. For us, this meant that we had to build the application fully equipped for smooth work under high loads and integrations with different internal systems of business users.
First, I suggest we see how things would go with traditionally used monoliths.
What if we chose a monolith
When a user opens the application to place an order, the system successively checks security, logs the user in, processes their request, sends an e-mail order confirmation – verifies the session is successfully completed. What’s wrong? Nothing is wrong. Taken out of context, the application just works as expected and fulfills its primary functions. In a perfect situation. However, here is what may have gone wrong in reality:
- Complete shutdown.
In a monolith, if one part of an app’s business logic doesn’t work or gets overloaded, the whole application may stop as it can’t proceed to the next operational stage. Back to our example, imagine that, for some reason, notifications cannot be sent right away. Users can’t get their orders successfully submitted until this part of the business logic becomes available again. As a result, the customer experience can be badly hindered.
- Complicated updates.
Imagine we need to upgrade a monolithic application (introduce new technologies, add new features). Even in case of minor changes, we’d need to rewrite pretty much of it, then stop the old version for some time (which means lost clients and orders) to replace it with a new one. Moreover, we’d have to be very careful and selective with newly introduced changes because they might damage the whole program.
- Frustrating UX.
As our monolith continues to develop and grow, it deals with a higher and higher load. In a monolith, the performance can hardly be scaled. Bad performance is one of the top reasons for lost customer loyalty. They won’t wait and can just buy from competitors. Luckily, this problem has a solution and here is what we do. Theoretically, to tackle a heavy load, we could duplicate the existing business logic. Then, we would get two identical servers and spread the load between them with a dynamic balancer that would randomly forward request to the less loaded one of them. It means that, if initially, one server processes, say, 200,000 QPS (queries per second), which made it too slow, now each of them deals with 100,000 QPS without experiencing overload. However, the maintenance of many servers is rather costly, and further scaling is under question.
What changes with microservices
Now, let’s see what the app designed as a set of several small and independent parts is like:
- Safe from complete shutdown
One server going slow because of an overload or even crashing completely doesn’t mean the end of the world. Often, the user won’t even notice any braking. When a user profile or order server is unavailable, the system will simply re-route the requests to its substitutes (as we have two user profile servers and three order servers). When the notification server crashes, the system will proceed with its work and resume the unavailable function as soon as the server is recovered. Yes, the client won’t get notifications right away, but, at least, their order won’t be rejected or lost.
- Easy updates
When the services are completely independent, we can just re-write the needed servers to add some new features (recommendation engine, fraud detection, etc.). In our example, when we need to introduce an IP tracker and report suspicious behavior (as Gmail does), we’ll just create a fraud detection server and slightly modify the user profile servers, while the rest of the servers stay safe.
- Great UX
The loosely coupled nature of the microservices architecture and its incredible potential for scaling allows tackling incidents with a minimal negative effect on user experience. For example, when we see that some of our core features run slow, we can scale up the number of servers handling the needed functions (as we did start with the user profile and order servers). Alternatively, we could let them go a little slow for a while if the features are not vital (as we did with the notifications). In some cases, it makes sense to disable some functions at all. For example, in peak times, we can have pop-ups that show only textual descriptions with no image included. This will require less capacity and positive user experience will be in place.
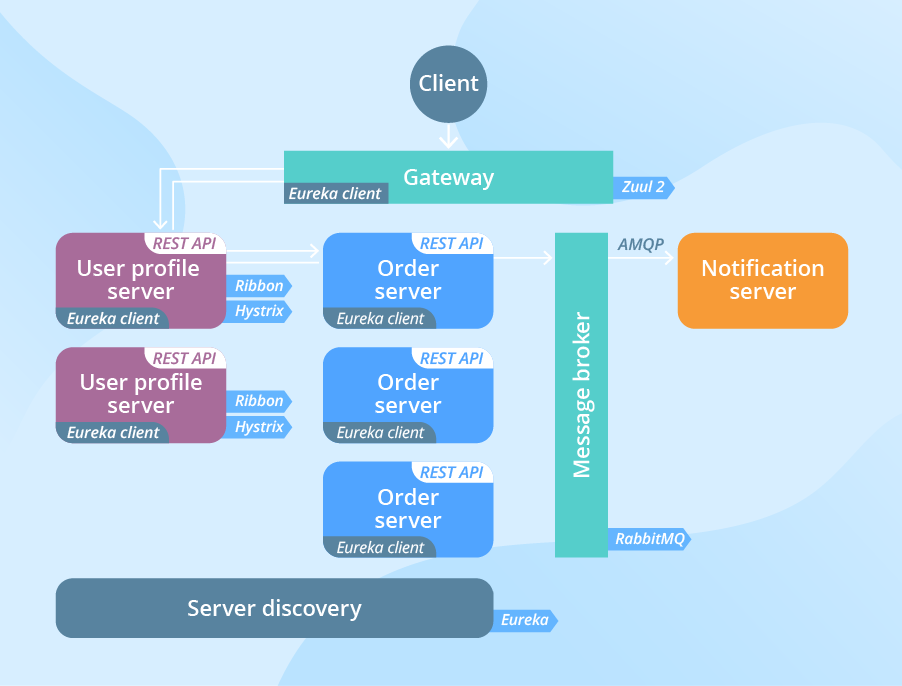
The technical part of the project
Now, I suggest we look at the technical part of the Java-based application implementation.
Step 1. We split it
We grained the application into microservices and got a set of units completely independent for deployment and maintenance. As already mentioned, in our application, 2 user profile servers, 3 order servers, and a notification server performed the corresponding business functions.
Step 2. We set up the message flow
However, splitting was only the starting point of building a microservice-oriented architecture. To make our system a success, it was more important and still even more difficult to ensure seamless communication between newly created distributed components. Our microservices communicated either via sync HTTP/REST or async AMQP protocols, depending on the need (as appropriate). If you need a quick update on the difference of sync and async calls, I recommend checking this explanation - it has been very popular among our clients and blog readers.
Also, we had to introduce several intermediate components.
- We implemented a gateway. The gateway became an entry point for all clients’ requests. It took care of authentication, security check, further routing the request to the relevant server, as well as of the request‘s modification or rejection. It also received the replies from the servers and returned them to the client. The gateway service exempted the client side from storing addresses of all the servers and made them independently deployable and scalable. As you remember, both features were of the utmost importance for us. For our gateway, we chose the new Zuul 2 framework. Since we wanted to achieve max performance scalability, it was important to leverage the benefits of non-blocking HTTP calls. And this is exactly what Zuul 2 granted us.
- The Eureka server worked as our server discovery. Since we had several servers per one function (and their number actually soon increased), server discovery was needed to keep a list of utilized user profile and order servers and help them discover each other.
- We also backed up our architecture with the Ribbon load balancer to ensure the optimal use of the scaled user profile servers.
- To ensure stronger fault tolerance and responsiveness of our system isolating the point of access to a crashed server, we used the Hystrix library. It prevented requests from going into the void in case the server is down and gave time to the overloaded one to recover and resume its work.
- As we didn’t want our users to wait for a positive response from the notification server to proceed with work, we needed the email notifications to be sent independently. For that, we used a message broker (RabbitMQ) as an intermediary between the notification server and the rest of the servers that allow async messaging in-between.
Are microservices a silver bullet?
Like any other architectural approach, microservices are not entirely flawless. The ‘splitting-for-splitting’ may not only turn out to be useless but also have a negative impact on your application. To learn about possible risks, you are welcome to check the detailed description of microservices pros and cons prepared by my colleague Henady Zakalusky.
Before embarking on such a large and long-lasting journey as microservices implementation, I would strongly recommend getting professional advice from expert Java architects. They would assess your particular needs and restrictions, and help figure out whether the microservices architecture will be feasible in your situation.
Achieve bigger results with microservices
If implemented right and in a good place, I see microservices as a huge help when it comes to creating complex applications that deal with huge loads and need continuous scaling. ScienceSoft's architects will be happy to perform the feasibility study and help you implement the microservices architecture safely and efficiently. Whether you want to start with microservices or migrate to them from an existing legacy monolith, just give us a shout.
