Metrics in Software Development: How To Implement the Practice and Have Efforts Justified

Related topics:
8 min read
Last updated:
In our software development practice, we distinguish two types of software development metrics: those helping assess resulting software and those giving insights into the development process. In the article, we explore the approach to designing and implementing effective metrics of both types.

How to apply software development metrics?
Project owners, project managers, development and QA teams may turn to software development metrics for:
Project management and planning
Measurement is a cornerstone of management. Software development metrics allow for a clear understanding of what and how teams have already done in the previous iterations of a project. Relying on the data, a project manager can better predict and plan budget, time, resources and requirements for upcoming iterations, as well as timely identify if an iteration or a whole project goes wrong.
Project overview
Metrics give the project owner a possibility to quickly understand and assess the project state, problems and how they are being resolved.
Task prioritization
Metrics are a good way to decide in which order the tasks should be performed to bring maximum value. For example, if user satisfaction score is low because of consistent dissatisfaction with the quality of updates that disrupt smooth functioning of software, it can be a signal to start dedicating more time in the course of an iteration to regression testing than to releasing a big bunch of new features.
Change management
Metrics can help understand whether there is any value out of changing an approach, a practice, a tool, etc., what value exactly can be expected and how it correlates with investments put in. For example, when switching to DevOps, such KPIs as the number of failed changes/deployments and mean time to recovery (MTTR) can help to assess the improvements that come with a change.
SLA monitoring and reporting, service adjustment
With KPIs, a customer can clearly communicate and track the value they expect (an increase in the frequency of releases, improved test coverage, a reduced number of features waiting in the backlog longer than the deadline or a reduced number of defects found in user acceptance testing (UAT) / in production) from an outsourcing vendor and understand how productive outsourced teams are. A vendor, in their turn, can vividly present the improvements that have been delivered.
What to measure?
Before we start, let us make it clear that the list of metrics should be decided on individually each time. To blindly copy the metrics set from some other project, simply track everything a project management tool offers or a software development framework prescribes is an unreasonable waste of time and effort. Metrics that do not answer any concrete question of project stakeholders or the ones whose results don’t have any potential effect on the project process should be avoided. As an example, for a real-time processing system, performance metrics will be a top priority, while for a distributed asynchronous system, metrics will center on availability.
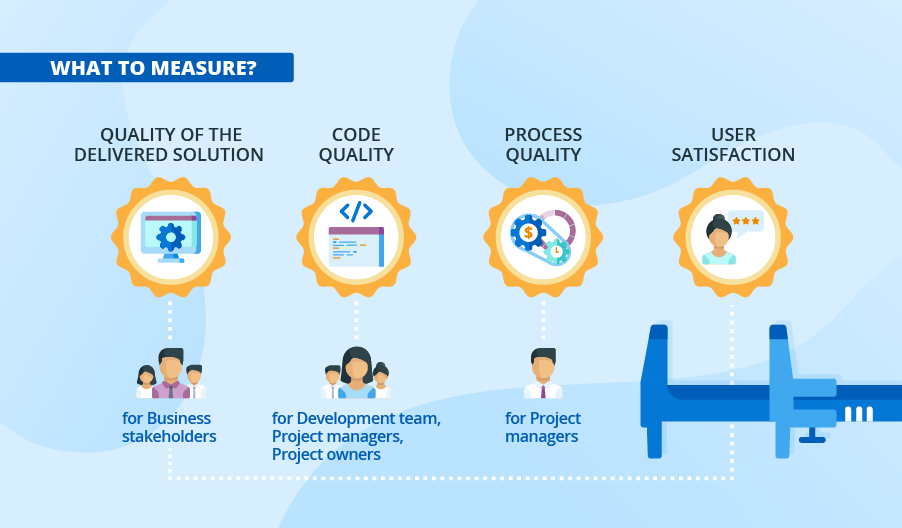
Quality of the delivered solution
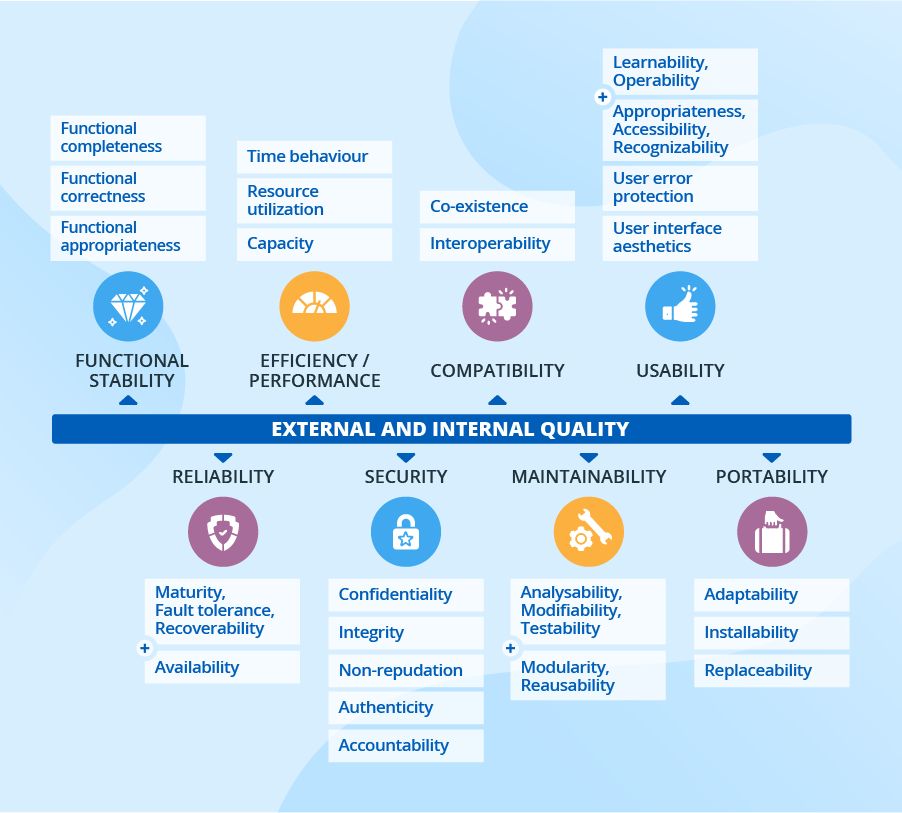
Business stakeholders are concerned with the external attributes (reliability, maintainability, etc.) of software. According to ISO/IEC 25010, the quality of modern software can be described with eight main attributes – being delivered to requirements, reliability, maintainability, compatibility, portability, security, usability, performance. Each of the attributes can be subdivided into a set of further characteristics and will require tracking a whole set of metrics to get the real picture. Further in the text, we’ll discuss how to deal with this type of metrics in more detail.
Code quality
The development teams, project managers and project owners want to know the quality of code they provide. Thus, team leads, architects and developers are interested in KPIs that can shed light on the technical part of the project, such as algorithmic complexity, the number of unnecessary dependencies, code churn, code duplication, test coverage, defect density and alike.
Process quality
Primarily, the project manager will be interested in tracking costs, resources, timelines and performance. They also need to understand the efficiency of the development processes established. Each programming paradigm, software development model and framework will have different indicators of success: for linear (traditional) development with a fixed scope, it is the percentage of scope complete, while agile and lean processes require the measurement of general lead time, cycle time, team velocity, etc.
User satisfaction
Measuring the satisfaction of the intended users is also of utmost importance. For a public product, it’ll be a customer satisfaction score, while for internal applications, assessments will be based on employee feedback. Interface consistency, the attractiveness of interactions, message clarity, interface element clarity, function understandability are examples of metrics suitable in both cases.
How to decide on the metrics to track?
Tracking all possible metrics requires significant input of effort and money. To draw up an effective list of metrics, a PM or a QA engineer (in cooperation with a project owner and business stakeholders when needed) should think of the key success factors for software and the project process. After that, they should proceed with a root cause analysis of each characteristic, moving to the actual data required to track the chosen aspect:
“15 minutes of blocked functionality in our ecommerce solution can cost us up to $20 000 in lost sales. We should try to improve the system availability to retain the expected level of revenue. What does the availability depend on? The number of failures, the duration of failures, the meantime to resume the service, etc.” – this is the right way to brainstorm the set of the needed metrics.
As you see, quality attributes depend on multiple factors, and each will require a certain set of metrics that you’ll need to track to get the comprehensive information. Let’s take reliability as an example. One of its characteristics resides in software maturity. Highly related metrics include the Lack of Cohesion in Methods (LCOM), Improvement of LCOM, and Tight Class Cohesion (TCC). Also, it is relevant to track such aspects as the Depth of Inheritance (DIT), Lack of Documentation (LOD), Response for a Class (RFC), and others.
How to implement metrics?
After the list of important high-level software aspects to track is established, the right process of metrics implementation will run as follows:
- Choosing the metrics formula.
You can use available off-the-shelf formulas – among the most famous are Halstead’s Metrics, McCabe’s Cyclomatic Complexity, Albrecht’s Function Point Analysis. Otherwise, you can create custom formulas, which are especially relevant for complex attributes.
Some metrics won’t need complex calculations and are, by their essence, a plain adaptation of measurement, for example, the number of features delivered over a sprint.
- Identifying the input data required for the measurement (and ensuring they’re available for tracking).
- Deciding where to take the input data for measurements.
The data can be provided by specific data owners. For example, testers can report on test coverage, test cases planned/executed and end users can provide info about problems they’ve encountered in interactions with software. The data sources can also be project management tools, source control management systems, CI and CD tools, application performance management tools, BI tools. Data can be gathered directly from end users through social network interactions (for products), survey forms, checklists, assessment questionnaires.
- Appointing a responsible person for metric tracking.
- Deciding with whom the results should be shared (for whom the received data will bring value).
- Deciding how often to report.
- Coming up with a mitigation plan in cases when metrics show unsatisfactory results.
- Regularly adjusting not working metrics.
An ideal set of metrics is almost impossible to come up with in the first run; it rather evolves in the course of the project by trial and error.
How to interpret software development metrics?
Considering metrics in isolation is a bad practice. For example, the Lines of Code (LOCs) metric is a count of code lines, including headers, comments, and declarations. It is used to assess the software size – and on this basis, estimate the efforts required to maintain software, a developer’s productivity and more. LOC has long been a popular metric since it’s easy to measure and automate. However, code lines differ in terms of complexity and functionality, and the number of comments in code can vary (it will increase in case of a distributed team or when code gets more complicated). So, if you base your productivity measurements on LOC exclusively, it’s highly possible that the results will be misleading.
Similarly, if a team delivers fewer new features than during previous iterations, it doesn’t necessarily mean that they are incompetent or less engaged. Instead, the team can be more focused on improvements of the already implemented releases based on user feedback). Also, the team may have to wait for other teams to complete their piece of work or lack proper communication with stakeholders regarding requirements specifications.
When interpreting software development metrics, always take the context into account. This will help to improve decision making and the overall project success.
