Speech Recognition in Healthcare Software
Technology Guide
In healthcare IT since 2005, ScienceSoft develops secure and efficient medical solutions with voice recognition capabilities.

The Essence of Speech Recognition in Healthcare
Speech recognition in healthcare converts clinician and/or patient speech into digital text in real time or from recorded audio. This technology can turn spoken input into accurate visit transcripts and clinician-ready notes (a.k.a. ambient scribing), and it can also enable AI voice assistants to interpret natural language during patient scheduling, intake, and follow-up calls.
Medical speech recognition solutions target the biggest administrative burdens in healthcare: documentation and patient service. Research on ambient clinical intelligence (ACI) shows it can reduce off-hours documentation for clinical care providers by 2.5 hours per week. Meanwhile, ScienceSoft’s pilot of a HIPAA-compliant voice agent for patient scheduling has shown potential to reduce appointment booking time by 40%, cut call abandonment rates by 30%, and process 70% more calls per hour than a patient service representative.
Healthcare Speech Recognition Market
The global voice and speech recognition market reached $8.49 billion in 2024 and is expected to reach $23.11 billion by 2030, with a 19.1% CAGR. The mounting demand for complex healthcare technologies is one of the main speech recognition market drivers. Two key vectors of segmental growth are patient medical record access (improving workflows and reducing time spent on manual data entry) and special-purpose AI agents (enabling natural interactions with patients and medical staff).
How Speech Recognition in Healthcare Works
Use cases
![]()
Clinical documentation
During in-person and virtual visits, the software records clinician dictation or clinician-patient conversations (with patient consent), converts speech into text via automatic speech recognition (ASR), and uses large language models (LLMs) to generate clinician-ready drafts, for example:
- SOAP (Subjective, Objective, Assessment, Plan) or H&P (History and Physical) notes.
- Problem and medication lists, structured findings.
- After-visit summaries (AVS) and patient instructions.
- Key moments and “highlights” with links to relevant transcript fragments for quick verification.
- Dictated clinical documents formatted into the required note sections and EHR fields (e.g., referral letters, discharge summaries, procedure notes).
![]()
Patient communication
AI voice agents can combine ASR, LLM-driven dialog, and integrations with clinical and administrative systems to autonomously handle live patient calls, for example:
- Schedule and reschedule appointments and confirm details (e.g., insurance, preferred time).
- Run intake questionnaires and collect pre-visit information with branching questions.
- Provide visit logistics and preparation guidance based on provider-approved content.
- Send and manage follow-ups and reminders through voice calls (with escalation rules for urgent cases).
- Route complex requests to staff and pass a structured handoff summary.
Architecture
Below, ScienceSoft solution architects present a high-level architecture for an ambient scribe solution built with open-source tools and explain how the ambient scribe pipeline operates end to end.
We recommend using open-source tools because they allow providers to host the solution on their own servers or in a private cloud, giving them more control over PHI handling. In addition, open-source software can be modified and customized to fit the provider’s specific needs. It may also help reduce costs at scale by lowering dependence on per-user or per-minute licensing fees.
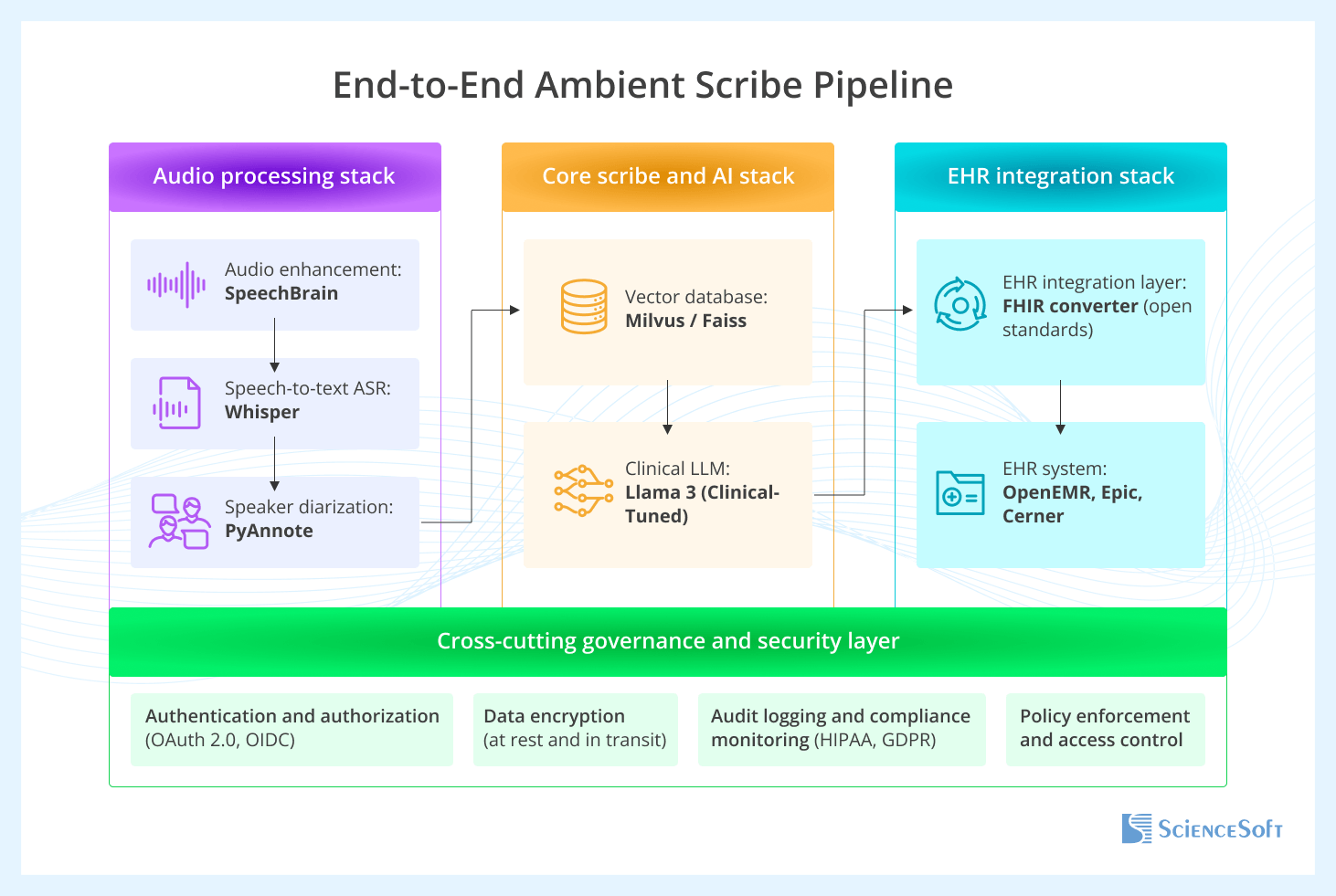
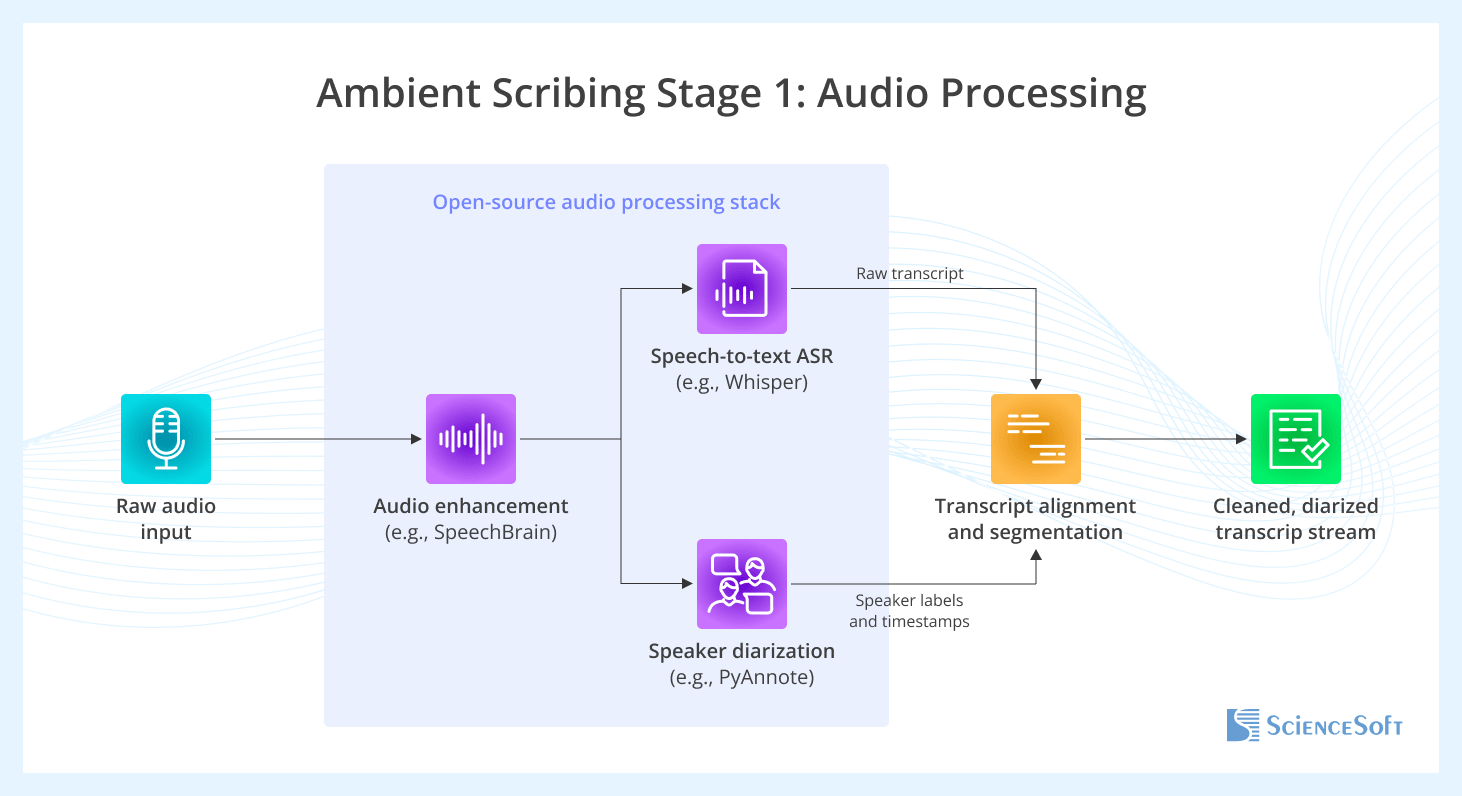
The first stage of the process takes the raw ambient audio and converts it into a clean, speaker-separated text transcript. First, raw audio is processed to remove background noise and improve clarity using tools like SpeechBrain. Next, an ASR (Automatic Speech Recognition) model, such as OpenAI's Whisper, converts the enhanced audio into a draft transcript. In parallel, a speaker diarization model like PyAnnote identifies who spoke when and assigns speaker labels and timestamps to audio segments. Finally, the transcript and diarization results are combined to create a single, clean, and diarized transcript stream.
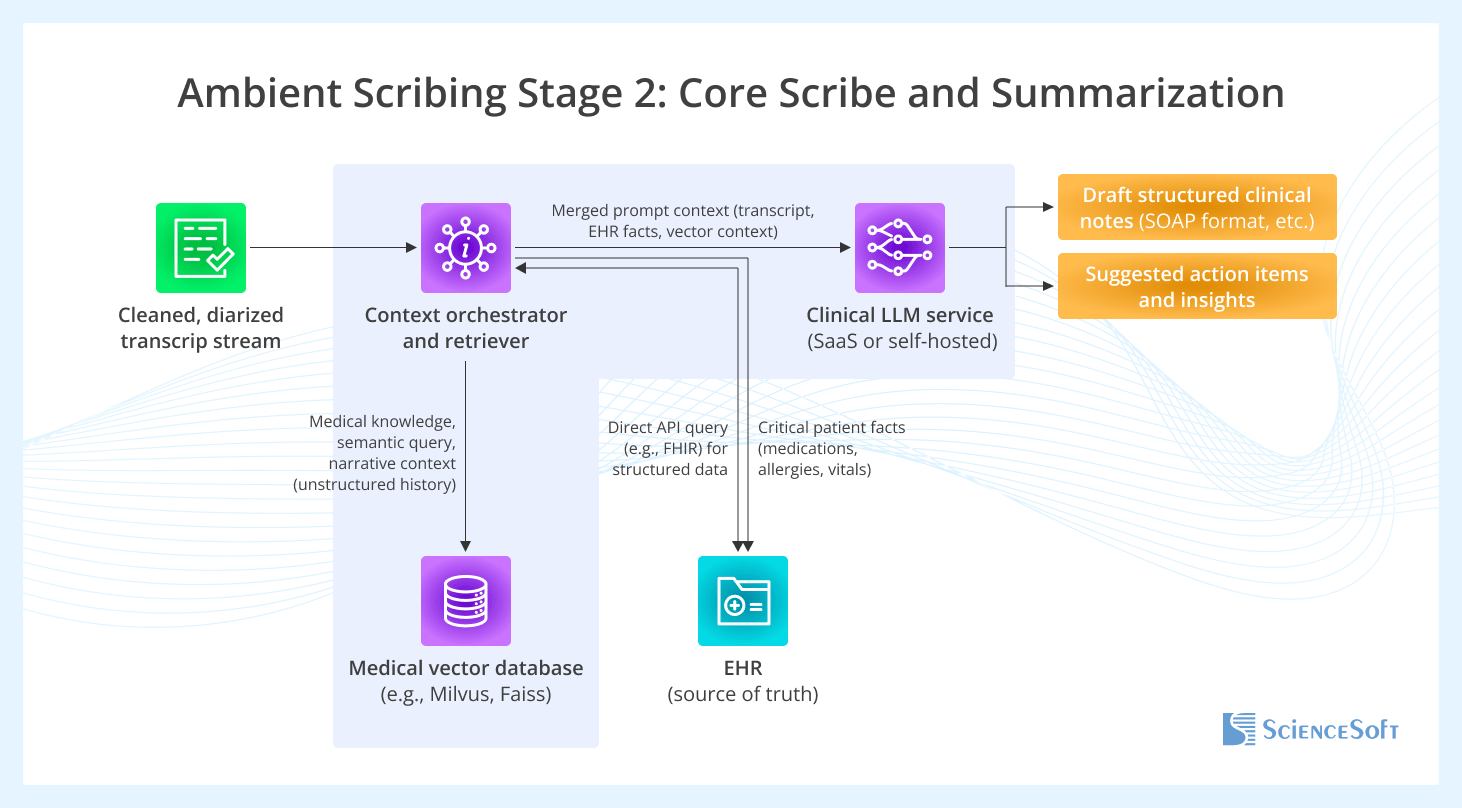
At stage two, the cleaned transcript is processed to generate structured clinical notes and suggested action items. This stage uses retrieval-augmented generation to ground LLM responses in provider-approved medical knowledge (stored in a vector database) or patient context retrieved directly from the EHR through HL7/FHIR-based interfaces. Depending on the use case, this context may include active problems, allergies, medications, recent procedures, lab results, care plans, and relevant prior notes. Using both the transcript and the retrieved context, the LLM (e.g., a clinically tuned version of Llama 3) generates structured drafts such as SOAP notes (Subjective, Objective, Assessment, and Plan) and suggested action items.
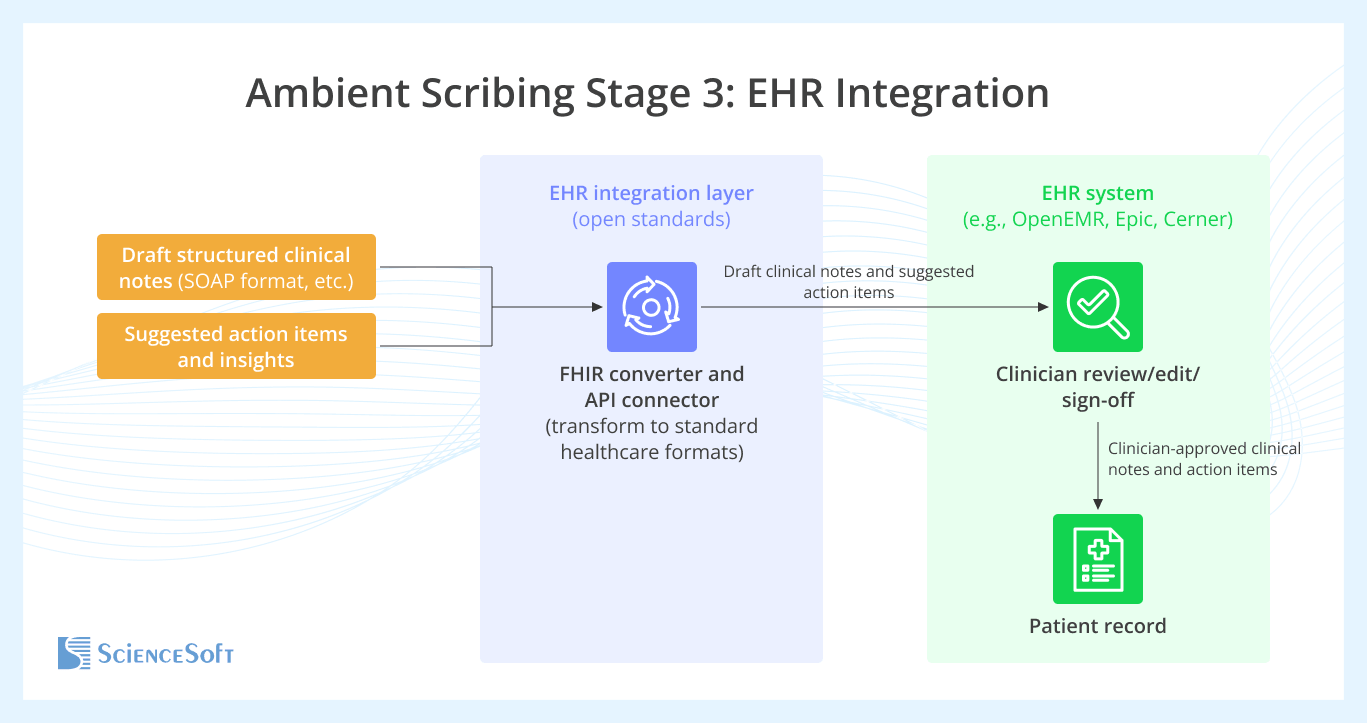
The third and final stage of the process delivers AI-generated drafts and insights into the provider’s EHR system, where they will be reviewed by staff. An integration layer acts as a bridge between the scribe application and the EHR: it converts the draft notes and suggested action items into standard healthcare data formats, most commonly HL7 or FHIR messages. The formatted data is then transmitted via secure APIs to the EHR system (e.g., OpenEMR, Epic, Cerner), where it is reviewed, edited if necessary, and approved by the clinicians. Only clinician-approved content is saved in the patient record.

Traditional speech recognition in healthcare is often used in a one-way, deferred mode: the system records speech and converts it into text for later review. Today, the same foundation can be extended to two-way, real-time voice agents by adding an LLM-driven dialog layer and text-to-speech (or speech-to-speech) capabilities, so the system can understand users and respond instantly. Since hospitals are increasingly adopting AI agents for administrative workflows, designing an architecture that supports both one-way scribing and two-way conversations can be more future-proof than deploying a transcription-only solution.
If you want your speech recognition tool to support live voice conversations with the user, you will need to add a text-to-speech (TTS) module or consider speech-to-speech models for more natural conversations. For example, Amazon Nova Sonic is designed for real-time speech-to-speech conversations and supports integrations with media and telephony platforms (including LiveKit and common telephony providers), which is useful when building voice agents.
In a recent project, we successfully applied Amazon Nova Sonic to build a voice AI scheduling agent for healthcare.

See Speech Recognition in Action
See how ScienceSoft’s AI Voice Assistant, powered by Amazon’s Nova Sonic Speech-to-Speech capabilities, can help a patient book an appointment. Hosted on AWS cloud and using the LiveKit Media server, the assistant can potentially reduce appointment booking time by 40% and cut call abandonment rates by 30%. You can find more details in our case study on the AI scheduling voice agent, including the solution’s detailed architecture.

Practical Value of AI Medical Scribes
In this interview, Hadeel Abu Baker explains how healthcare providers can use AI medical scribes to reduce documentation work and support smoother patient visits. She also outlines what safe adoption requires, including human review, sound workflow design, and realistic expectations for automation.
Technologies We Use for Speech AI in Healthcare
Speech recognition, diarization, and speech-to-speech models
Parakeet
Canary
pyannote.audio
TitaNet
ECAPA-TDNN
Amazon Transcribe Medical
Google Cloud Speech-to-Text
Amazon Nova 2 Sonic
General-purpose LLMs
Llama 3
OpenAI GPT
Google Gemini
Anthropic Claude
Healthcare-specific language models
MedGemma
MedLM
BioMedLM
GenAI platforms and services
OpenAI
Microsoft Foundry
Amazon Bedrock
Google Vertex AI
OCI Generative AI
Hugging Face
Core AI frameworks and libraries
PyTorch
Hugging Face Transformers
NVIDIA NeMo
SpeechBrain
Agents and orchestration
OpenAI Agents SDK
Amazon Bedrock Agents
Google Agent Development Kit (ADK)
LangChain
LangGraph
Dify
n8n
Telephony, real-time media, and voice communication platforms
Amazon Connect
Amazon Chime SDK
LiveKit
Twilio
Azure Communication Services
SIP
WebRTC
Vector search and knowledge retrieval
Faiss
Zilliz (Milvus)
ChromaDB
Qdrant
Weaviate
Pgvector
OpenSearch
In most cases, ASR and language models are best used as separate, testable layers. Clinical-grade ASR and medical vocabularies help ensure a reliable transcript, while LLMs are typically used after transcription to structure clinical notes, generate patient-ready summaries, and support workflow actions. To improve control and reduce latency, we often rely on small language models (SLMs) or fine-tuned domain models for extraction and structuring tasks. Outputs should always be constrained and verified using templates, approved terminology, trusted sources, and clinician review.
How to Tackle the Challenges of Speech Recognition for Healthcare
Challenge: Medical language specificity, accents, and dialects can cause transcript errors.
ScienceSoft experts improve transcription accuracy with specialty dictionaries, abbreviation handling, contextual biasing for patient names and medications, audio-quality controls, and post-ASR cleanup for punctuation, units, and normalization. In dialect-heavy scenarios, we focus on reducing transcription errors before they affect downstream clinical documentation. When domain-specific medical data are limited, ScienceSoft relies on strong multilingual models instead of custom training. We also add confidence checks so the system can ask clarifying questions or escalate to staff when needed, and we use correction workflows to continuously improve vocabularies and configuration.
Challenge: LLMs can produce hallucinations and “confidently wrong” summaries.
ScienceSoft reduces hallucination risks by constraining outputs to clinical templates such as SOAP and H&P, grounding generation in provider-approved content and permitted patient context, and linking generated statements to transcript fragments for traceability. For clinical documentation, we also keep clinician review and sign-off mandatory.
Challenge: Using third-party speech and GenAI services can increase PHI protection risks.
ScienceSoft recommends sharing only the minimum data needed with third-party speech and GenAI services. We remove or mask unnecessary identifiers, limit prompts and retrieval to the active patient’s case, and avoid sending full records when a smaller clinical excerpt is enough. We protect the core healthcare environment with role-based access, least-privilege permissions, multi-factor authentication, encryption in transit and at rest, and full audit trails. For AI integrations, we add isolated workloads, tightly scoped service access, short-lived credentials, and controlled API connections. Depending on security and data residency requirements, ScienceSoft can deploy AI components in a private cloud, inside a VPC, or on premises.
When external AI providers are involved, ScienceSoft gives preference to vendors with healthcare-ready terms and controls, such as Microsoft and AWS. We verify BAA readiness, where data is stored and processed, retention and deletion rules, whether customer data can be used for model training, and available compliance documentation.
To prevent one patient’s data from appearing in another patient’s workflow, we apply different controls depending on the solution type. In ambient scribing, we bind transcripts and summaries to the active visit or appointment using patient, clinician, and scheduling context. In voice-agent workflows with retrieval and automation, we also restrict retrieval to the active patient record and add confirmation steps before patient-specific content is shown to a user or written to connected systems such as the EHR, portal, or messaging tools. If the system cannot match the interaction to the right visit with high confidence, ScienceSoft requires user confirmation or routes the case for staff review. We apply this confidence-based escalation in both voice-agent and ambient-scribe solutions.
How Much Does It Cost to Build Healthcare Software for Speech Recognition?

Healthcare speech recognition software cost typically ranges from $40,000 to $250,000+, depending on the solution type and scope. Based on ScienceSoft’s experience, basic speech-to-text transcription with EHR write-back can start at around $40,000. An ambient scribe MVP that supports a single note format for one specialty typically costs $80,000 to $150,000. Production-grade ambient scribes with deeper workflow logic and multi-specialty support, as well as healthcare voice agents with telephony and full EHR integration, generally fall in the $150,000 to $250,000+ range.
Need a precise cost estimate for medical speech recognition software?
Key cost factors we consider:
- The scope and complexity of the solution (dictation vs. ambient scribing vs. voice agents, real-time vs. deferred processing).
- Performance requirements that affect architecture and effort (latency targets, concurrency, uptime).
- The number and complexity of integrations (EHR, scheduling, telephony, patient apps, RPM systems, contact center tools).
- UI and UX effort for the required user journeys and interfaces.
- Knowledge grounding work (RAG): preparing, validating, and maintaining provider-approved content and retrieval pipelines.
- AI safety, quality, and evaluation needs (designing safety controls, testing, monitoring, drift detection, and incident handling).
- Security and compliance implementation (PHI protection, access control, audit logs, data retention, and meeting applicable regulations).
- Support, maintenance, and ongoing optimization (model updates, prompt and template adjustments, and integration upkeep).
Launch a Speech Recognition Solution for Healthcare
With 150+ successful projects for the healthcare industry, ScienceSoft helps software companies and healthcare providers implement secure speech solutions, from ASR-based transcription to LLM-powered AI scribing and voice agents. You set the goals, and we deliver the solution within your timelines and budget, adapting to changing requirements while maintaining quality, security, and compliance.

Speech recognition consulting
Need professional assistance to implement speech recognition? ScienceSoft’s healthcare IT experts can suggest the optimal technology and architecture, guide you through project planning, and assist with risk management.

Speech recognition implementation
ScienceSoft delivers end-to-end healthcare speech solutions, from UX and architecture design to development, integrations, testing, deployment, monitoring, and ongoing improvement.
