End-to-End Big Data Applications
Use Cases, Architecture, Gains
In big data services since 2013, ScienceSoft helps organizations across 30+ industries build tailored end-to-end big data applications that support smooth business operations and enable accurate analytics results.

The Global Big Data and Analytics Market Is to Reach $662 Billion by 2028
According to the Mordor Intelligence, the global big data and analytics market is expected to reach $375.76 billion by 2030, compared to $234.27 billion in 2025, growing at a CAGR of 9.91%. The market growth drivers are the increasing volume and variety of data, the wide adoption of cloud computing, and the rising need for data-driven decision-making.
The major applications of big data include customer analytics (accounts for the biggest market share), supply chain analytics, marketing analytics, pricing analytics, workforce analytics, and more.
In the 2024 Data and AI Leadership Executive Survey that features over 100 leading organizations from diverse industries (incl. healthcare, insurance, investment, finance, retail, manufacturing, IT, telecoms, media, and education), 87% of respondents report measurable business value from their data and analytics investments.
End-to-End Big Data Applications: The Essence
End-to-end big data applications enable fault-tolerant, low-latency processing of massive data volumes coming from multiple sources, in various formats, and in both scheduled and unpredictable patterns.
End-to-end big data applications can be operational or analytical and can also present a combination of both types.
Operational end-to-end big data apps enable the processing of large, real-time, interactive workloads while preserving stable performance to ensure a smooth user experience. Examples of operational big data apps include social media, ridesharing platforms, e-marketplaces, large-scale IoT systems.
Analytical end-to-end big data apps use batch or real-time analysis of voluminous, multi-source data to enable predictive and prescriptive analytics, generate real-time alerts, and more.
High-Level Architecture of an End-to-End Big Data Application
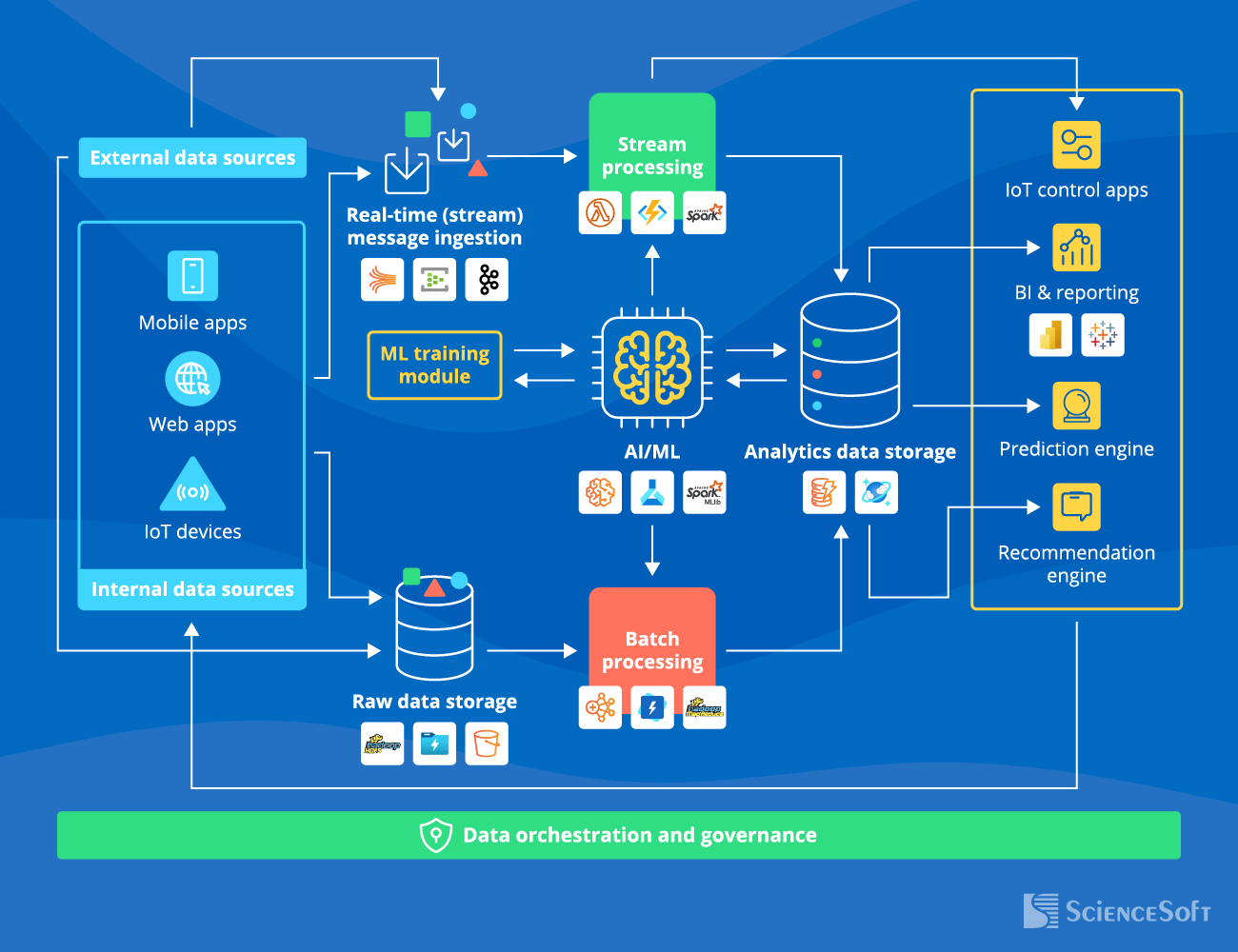
Below, ScienceSoft's software engineering experts outline the most vital architecture blocks of an end-to-end big data application. Such an app can include all or several components present in the picture above.
- The data sources include internal sources like mobile and web apps gathering user-generated data, IoT devices (sensors, smart devices, wearables), and external sources (e.g., market and weather data, social media content).
- Raw data storage is a data lake that stores data for further batch processing. At this stage, any data is stored in its initial format and can be structured, unstructured, or semi-structured.
- The real-time (stream) message ingestion engine captures real-time messages (e.g., IoT readings, user app requests) and directs them for stream processing to enable immediate system response. The ingestion engine also directs real-time messages to the raw data storage to preserve it in the initial form (incl. metadata) for future analytics purposes.
- The stream processing module processes new messages or events in near real-time. In contrast, the batch module does it according to the established computation schedule (e.g., every hour, 24 hours, month), enabling cost-effective processing of voluminous historical data. If you want to know more about their differences and advantages, check out our dedicated guide.
- Analytics data storage is a data warehouse storing highly structured pre-processed data as well as analytical results ready for querying in big data analytics applications. The analytics output then goes either to the reporting tools or back to the data sources (e.g., sending action triggers to IoT actuators or returning ecommerce customers’ search requests).
- The AI/ML engine is an optional module that analyzes the structured data from the analytics data storage, produces intelligent insights (e.g., detecting pre-failure equipment conditions, predicting customer behavior), and feeds these insights into the corresponding processing modules. An accompanying ML training module is needed to update the engine, continuously improving its accuracy.
- Data orchestration and governance system automates repeating data processing operations (e.g., transforming source data and moving it between the architecture modules) and ensures complete data quality, protection, and compliance throughout the analytics lifecycle.
Techs and Tools To Build End-to-End Big Data Applications
Raw data storage
- Amazon S3
- Azure Data Lake
- Azure Blob Storage
- Azure Files
- Google Cloud Storage
- Microsoft Fabric
- HDFS
Stream message ingestion
- Apache Kafka
- Azure IoT Hub
- Azure Event Hubs
- AWS IoT Core
- Amazon Kinesis
- Google Cloud Dataflow
Stream processing
- Amazon Managed Streaming for Apache Kafka
- AWS Lambda
- Azure Functions
- Google Cloud Functions
- Microsoft Fabric
- Apache Storm
- Apache Spark
Batch processing
- Azure Data Lake Analytics
- Azure HDInsight
- Amazon EMR
- Google Cloud Dataproc
- Google Cloud Dataflow
- Google Cloud Data Fusion
- Google Cloud Data Catalog
- Microsoft Fabric
- Pig
- Apache Hive
- Apache Sqoop
- Hadoop MapReduce
Analytics data storage
- Amazon Redshift
- Amazon DynamoDB
- Azure Stream Analytics
- Azure Synapse Analytics
- Azure Cosmos DB
- Google Cloud Datastore
- Microsoft Fabric
- Apache Hive
- MongoDB
AI/ML
ML framework and libraries
- Apache Mahout
- Apache MXNet
- Caffe
- TensorFlow
- Keras
- Torch
- OpenCV
- Apache Spark MLlib
- Theano
- Scikit Learn
- Gensim
- SpaCy
Platforms and services
- Azure Cognitive Services
- Microsoft Fabric
- Microsoft Bot Framework
- Azure Machine Learning
- Amazon SageMaker AI
- Amazon Lex
- Amazon Transcribe
- Amazon Polly
- Google Cloud AI Platform
Data orchestration and governance
- Apache Airflow
- Talend
- Informatica
- Zaloni
- Apache ZooKeeper
- Azkaban
BI & reporting
- Power BI
- Microsoft Fabric
- Microsoft SQL Server
- Microsoft Excel
- Google Developers Charts
- Tableau
- Grafana
- Chartist.js
- FusionCharts
- DataWrapper
- Infogram
- ChartBlocks
- D3.js
- Oracle Business Intelligence
- MicroStrategy
- QlikView
- Sisense
- Kyubit Business Intelligence
Defining ‘Big’ in Big Data Applications

With big data being quite a buzzword recently, many businesses wonder if their data volume is large enough to be considered ‘big.’ Often, the focus is on the numbers, like 100TB or 1PB. However, this approach is misleading.
Your data is big as soon as you see that traditional technologies and out-of-the-box solutions can’t handle it anymore. If conventional techs can’t enable the smooth operation of your data-rich apps or provide analytics results on time, your data is already voluminous enough to warrant big data implementation.
Why Entrust Your Big Data Project to ScienceSoft
- Since 1989 in custom software development, data analytics, and data science.
- Since 2013 in big data solution development.
- Practical experience in 30+ industries, including healthcare, insurance, investment, banking, lending, manufacturing, retail, logistics, energy, and telecoms.
- A team of business analysts, solution architects, data engineers, and project managers with 5–20 years of experience.
- ISO 9001 and ISO 27001-certified to guarantee top service quality and complete security of our clients’ data.
Our satisfied clients
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()





Big Data: You Envision It, We Make It Work
Over the past decade, we have successfully implemented big data to serve the unique needs of dozens of our clients — and we are ready to apply our skills and expertise to make it work for you. With established project management practices for scoping, cost estimation, risk mitigation, and other aspects, we prioritize driving the project to its goals regardless of time and budget constraints.

Big data consulting
Our big data consultants and architects are here to guide you through your big data adoption journey. We can build a business case, design the software architecture, offer a viable tech stack, and help you optimize the project costs.

Big data implementation
With years of experience, we know how to build sustainable solutions that bring the expected outcomes instead of a bloated project budget and years-long development. And we’ll be glad to design and implement your big data app with the focus on making it fast, fault-tolerant, secure, cost-effective, and loved by users.
|
|
|
|
|
How data accessibility fuels financial growth“For a typical Fortune 1000 company, just a 10% increase in data accessibility will result in more than $65M additional net income.” – Richard Joyce, Senior Analyst at Forrester. |
|
|
|


May Your Big Data App Meet and Exceed Your Expectations
And if you need a skilled team to deliver it, ScienceSoft is here to lend a helping hand.
