The ‘Scary’ Seven: Big Data Challenges and Solutions to Them

Related topics:
Last updated:
Before going to battle, each general needs to study his opponents: how big their army is, what their weapons are, how many battles they’ve had and what primary tactics they use. This knowledge can enable the general to craft the right strategy and be ready for battle.
Just like that, before going big data, each decision maker has to know what they are dealing with. Here, our big data consultants cover 7 major big data challenges and offer their solutions. Using this ‘insider info’, you will be able to tame the scary big data creatures without letting them defeat you in the battle for building a data-driven business.
First, let’s look at the market situation. The survey by Matillion and IDG reveals that the amount of data at enterprises grows by 63% each month, and 12% of the surveyed organizations reported an increase of 100%. Businesses see data as the cornerstone for making decisions in multiple areas. Statista says that 75% of businesses worldwide use data to drive innovation, and 50% report that data helps them to compete in the market. A survey by Digital Reality indicates that more than 50% of organizations use data to develop new products and services, enhance customer satisfaction and experience, and mitigate risks and cybersecurity breaches.
So, it’s not surprising that many industries adopt big data. For examples, adoption of big data and AI in healthcare, financial services, and telecoms varies between 90% and 100%. Spice these stats up with the fact that big data is inseparable from omnipresent AI tools and analytics, and you’ll be fully convinced that all big data challenges are worth overcoming.

Challenge #1: Insufficient Understanding And Acceptance of Big Data
Oftentimes, companies fail to know even the basics: what big data actually is, what its benefits are, what infrastructure is needed, etc. Without a clear understanding, a big data adoption project risks to be doomed to failure. Companies may waste lots of time and resources on things they don’t even know how to use.
And if employees don’t understand big data’s value and/or don’t want to change the existing processes for the sake of its adoption, they can resist it and impede the company’s progress.
Solution:
Big data, being a huge change for a company, should be accepted by top management first and then down the ladder. To ensure big data understanding and acceptance at all levels, IT teams need to organize numerous trainings and workshops.
To see to big data acceptance even more, the implementation and use of the new big data solution need to be monitored and controlled. However, top management should not overdo with control because it may have an adverse effect.
Challenge #2: Confusing Variety of Big Data Technologies

It can be easy to get lost in the variety of big data technologies now available on the market. Do you need Spark or would the speeds of Hadoop MapReduce be enough? Is it better to store data in Cassandra or HBase? Finding the answers can be tricky, and wrong technology choices can lead to poor solution performance and low cost-efficiency, making it impossible to reach a positive ROI.
Solution:
If you are new to the world of big data, trying to seek professional help would be the right way to go. You could hire an expert or turn to a vendor for big data consulting. In both cases, with joint efforts, you’ll be able to work out a strategy and, based on that, choose the needed technology stack.
Read more:
- Spark vs. Hadoop MapReduce: Which big data framework to choose
- Apache Cassandra vs. Hadoop Distributed File System: When Each is Better
- Cassandra vs. HBase: twins or just strangers with similar looks?
Challenge #3: Paying Loads of Money
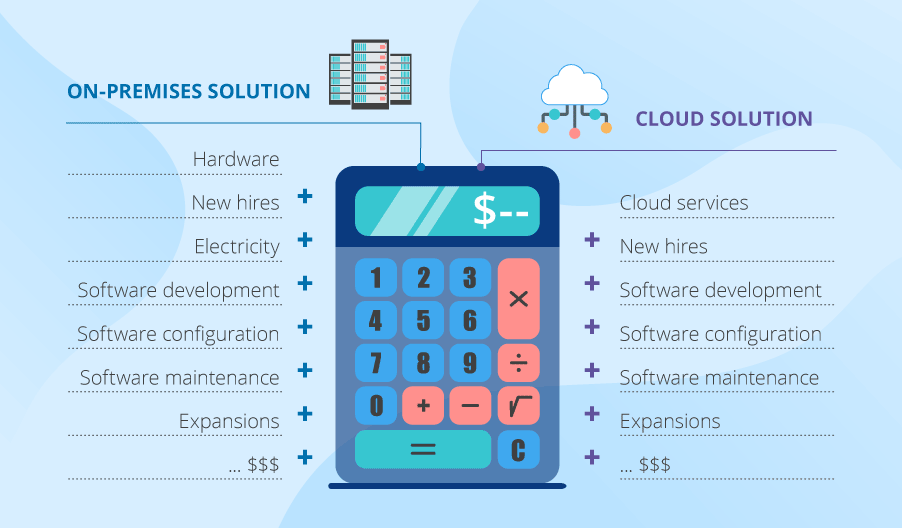
Big data adoption projects entail lots of expenses. If you opt for an on-premises solution, you’ll have to mind the costs of new hardware, new hires (administrators and developers), electricity, and so on. Plus: although the needed frameworks are open-source, you’ll still need to pay for the development, setup, configuration and maintenance of new software.
If you decide on a cloud-based big data solution, you’ll still need to hire staff (as above) and pay for cloud services, big data solution development as well as setup and maintenance of needed frameworks.
Moreover, in both cases, you’ll need to allow for future expansions to avoid big data growth getting out of hand and costing you a fortune.
Solution:
The particular salvation of your company’s wallet will depend on your company’s specific technological needs and business goals. For instance, companies who want flexibility benefit from cloud. While companies with extremely harsh security requirements go on-premises.
There are also hybrid solutions when parts of data are stored and processed in cloud and parts – on-premises, which can also be cost-effective. And resorting to data lakes or algorithm optimizations (if done properly) can also save money:
- Data lakes can provide cheap storage opportunities for the data you don’t need to analyze at the moment.
- Optimized algorithms, in their turn, can reduce computing power consumption by 5 to 100 times. Or even more.
All in all, the key to solving this challenge is properly analyzing your needs and choosing a corresponding course of action.
Challenge #4: Complexity of Managing Data Quality
Data from diverse sources
Sooner or later, you’ll run into the problem of data integration, since the data you need to analyze comes from diverse sources in a variety of different formats. According to the Digital Reality survey we linked above, enterprises deal with an average of 400 sources. For instance, ecommerce companies need to analyze data from website logs, call centers, competitors’ website ‘scans’ and social media. Data formats will obviously differ, and matching them can be problematic. For example, your solution has to know that skis named SALOMON QST 92 17/18, Salomon QST 92 2017-18 and Salomon QST 92 Skis 2018 are the same thing, while companies ScienceSoft and Sciencesoft are not.
Unreliable data
Nobody is hiding the fact that big data isn’t 100% accurate. And all in all, it’s not that critical. But it doesn’t mean that you shouldn’t at all control how reliable your data is. Not only can it contain wrong information, but also duplicate itself, as well as contain contradictions. And it’s unlikely that data of extremely inferior quality can bring any useful insights or shiny opportunities to your precision-demanding business tasks.
Solution:
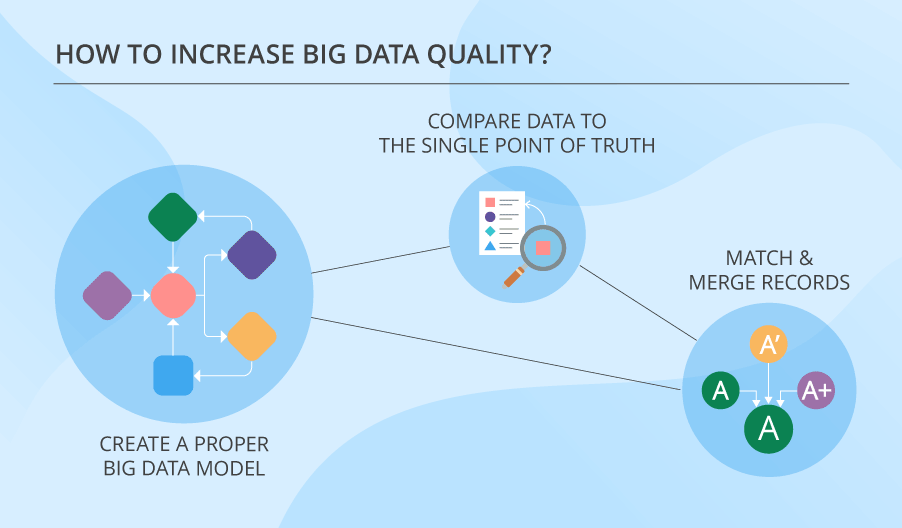
There is a whole bunch of techniques dedicated to cleansing data. But first things first. Your big data needs to have a proper model. Only after creating that, you can go ahead and do other things, like:
- Compare data to the single point of truth (for instance, compare variants of addresses to their spellings in the postal system database).
- Match records and merge them, if they relate to the same entity.
But mind that big data is never 100% accurate. You have to know it and deal with it, which is something this article on big data quality can help you with.
Challenge #5: Demanding Data Governance
Data governance is about ensuring data integrity, regulatory compliance, and security throughout its lifecycle. According to Precisely, 71% of organizations have a data governance program, and the majority report significant benefits. For example, 58% noticed improved quality of data analytics and insights, another 58% improved their data quality, and 57% achieved better collaboration. At the same time, more than half of the respondents see data governance as one of their top challenges. Here are the major reasons for big data governance being so complex:
- Big data is mostly unstructured (e.g., video, audio, text files), which makes it harder to classify and secure.
- There are big data security challenges that are more demanding than the complexities of traditional data. The common problems include delayed threat detection due to data velocity, cross-border legal risks, inference attacks via aggregated data.
- Big data is associated with AI-powered analytics and real-time processing tasks. It is difficult to build a system that will provide real-time output and answer data security and integrity requirements at the same pace. Plus, AI introduces the need to perform data audits to ensure ethical use and avoid biased decisioning.
A poor data governance framework can result in significant losses for businesses. For example, IBM states that the global average cost of a data breach in 2024 amounted to $4.88 million, and Gartner says that low data quality costs organizations at least $12.9 million a year on average.
Solution:
Here are the major aspects you should pay attention to when building a big data governance framework:
- Introducing mechanisms for ensuring high quality of big data, e.g., the ones for cleansing, profiling, and monitoring.
- Assigning data stewards to oversee compliance with data policies across the organization.
- Introducing mature security measures to preserve data privacy and integrity.
- Using advanced technologies to enhance data governance. For example, AI-powered tools can identify sensitive data, recommend or automatically enforce policies to secure it, and flag anomalies in real time. One can also consider cloud-based solutions as they support more data governance tools compared to on-premise deployments.
Challenge #6: Tricky Process of Converting Big Data Into Valuable Insights
A Clootrack survey says that 18% of businesses find it challenging to transform data into insights, and the above-mentioned survey by Digital Reality indicates the reasons. They include insufficient investment in data analytics tools and infrastructure, customer reluctance to share data, and lack of data centralization.
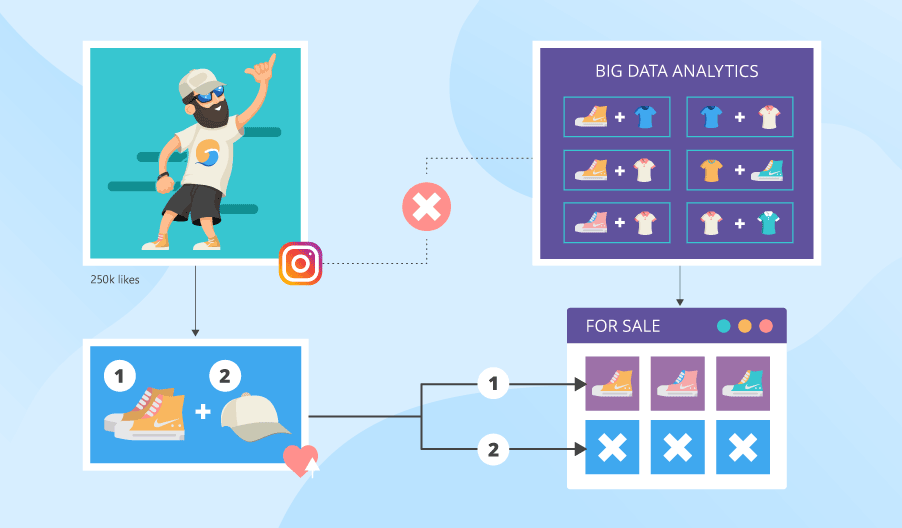
Here’s an example of how the lack of proper analytics tools can prevent businesses from driving game-changing insights. Your big data analytics looks at what item pairs people buy, solely based on historical data about customer behavior. Meanwhile, on Instagram, a certain soccer player posts his new look in white Nike sneakers and a beige cap. He looks good in them, and people want to look this way too. Thus, they rush to buy a similar pair of sneakers and a similar cap. But your store has run out of beige caps, and you have only the sneakers. As a result, you lose revenue and maybe some loyal customers. Meanwhile, your competitor’s analytics picked up on the emerging trends just in time. So, the competing shop has both items and even offers a 15% discount if you buy both.
Solution:
The idea here is that you need to create a proper system of factors and data sources that need to be taken into account by the big data analytics engine. Such a system should often include external sources, even if it may be difficult to obtain and analyze external data.
Find consultants who will review your business processes and big data analytics system to suggest improvements that will allow you to maximize data value. You can see how ScienceSoft helped a multibusiness corporation get rid of data silos and centralize data from 15 disparate data sources, which let the business get a 360-degree customer view, optimize stock management, and get other analytics-driven benefits.
Recently, AI tools have emerged and demonstrate good results in enhancing analytics. For example, AI helps improve the accuracy of forecasts, especially in real-time scenarios such as payment fraud detection. AI also lets democratize analytics, making it easily available to non-technical users. For a practical example, you can check our ScienceSoft’s demo of a Power BI chatbot that lets users get financial reports based on natural language commands. The development costs of such solutions can range from $30,000 to $1,000,000, but at the same time, a Forrester study indicates that 63% of data and analytics leaders believe they make faster and better decisions by applying AI/ML to their data.
Challenge #7: Troubles of Upscaling
The most typical feature of big data is its dramatic ability to grow. And one of the most serious challenges of big data is associated exactly with this.
Your solution’s design may be thought through and adjusted to upscaling with no extra efforts. But the real concerns are not about introducing new processing and storing capacities. It lies in the complexity of scaling up so, that your system’s performance doesn’t decline, and you stay within budget. If your system can’t be adapted to data growth without major rework, you’ll have to face repeated investments and downtimes. Here, you can see how ScienceSoft helped a US retailer accommodate big data growth and achieve 100x faster data processing without disrupting business operations.
Solution:
The first and foremost precaution for technical challenges like this is a decent architecture of your big data solution. As long as your big data solution can boast such a thing, less issues are likely to occur later. Another highly important thing to do is designing your big data algorithms while keeping future upscaling in mind.
But besides that, you also need to plan for your system’s maintenance and support so that any changes related to data growth are properly attended to. And on top of that, holding systematic performance audits can help identify weak spots and timely address them.
Big Data Challenges and Their Solutions In a Nutshell
| Challenge | Solution |
|
1. Insufficient understanding and acceptance of big data. |
Arrange trainings and workshops, monitor technology adoption, and take corrective measures. |
|
2. Confusing variety of big data technologies. |
Turn to experts to choose techs that will ensure an optimal combination of performance, security, cost-efficiency, and other parameters. |
| 3. Paying loads of money. | Consider building a data lake to reduce raw data storage expenses and optimizing processing algorithms to reduce compute resources. |
|
4. Difficulty of managing data quality. |
Create a shared data model, compare data to the single point of truth, match and merge records, and monitor data quality. |
|
5. Complex data governance. |
Create a robust data governance framework, including data stewardship, data quality, data security, and compliance management. Implement advanced tools such as AI-powered policy enforcement. |
|
6. The tricky process of converting big data into valuable insights. |
Consider adding new analytics tools (e.g., real-time and A-powered analytics), eliminating data silos, and enhancing analytics infrastructure. |
|
7. Troubles of upscaling. |
Design future-proof big data architecture and algorithms. In case your current architecture already needs a revamp, make sure the new version is ready for data growth. Plan for continuous system maintenance and support. |
Win or Lose?
As you could have noticed, most of the reviewed challenges can be foreseen and dealt with, if your big data solution has a decent, well-organized and thought-through architecture. And this means that companies should undertake a systematic approach to it. But besides that, companies should:
- Hold workshops for employees to ensure big data adoption.
- Carefully select technology stack.
- Mind costs and plan for future upscaling.
- Remember that data isn’t 100% accurate but still manage its quality.
- Dig deep and wide for actionable insights.
- Never neglect big data security.
If your company follows these tips, it has a fair chance to defeat the Scary Seven.
