Your Guide to Data Quality Management

Related topics:
Last updated:
Editor's note: In the article, Irene reveals some tips on how a company can measure and improve the quality of their data. If you want to organize your data management process promptly and correctly, we at ScienceSoft are ready to share and implement our best practices. For more information, check our data management services.
One of the crucial rules of using data for business purposes is as simple as this: the quality of your decisions strongly depends on the quality of your data. In fact, according to Gartner, poor data quality costs organizations at least $12.9 million a year on average. A survey by Monte Carlo says that businesses report 31% of their revenue being impacted by data quality issues. A report by Experian features stats at an optimistic angle: 75% of organizations that improved their data quality management exceeded their business goals.
However, just acknowledging the importance of data quality management isn’t too helpful. To get tangible results, you should measure the quality of your data and act on these measurements to improve it. Here, we throw some light on complicated data quality issues and share tips on how to excel in resolving them.
How to Define Data Quality: Attributes, Measures, and Metrics
It would be right to start this section with a universally recognized definition of data quality. But here comes the first trouble: there is none. In this respect, we can rely on our experience in data analytics and take the liberty to offer our own definition: data quality is the state of data, which is tightly connected with its ability (or inability) to solve business tasks. This state can be either “good” or “bad”, depending on to what extent data corresponds to the following attributes:
- Consistency
- Accuracy
- Completeness
- Auditability
- Orderliness
- Uniqueness
- Timeliness.
To reveal what’s behind each attribute, our data management team put together this table and filled it with illustrative examples based on customer data. We also mentioned sample metrics that can be chosen to get quantifiable results while measuring these data quality attributes.
Data quality attributes
| Attribute | What it means | Example of good practice | Example of bad practice | Metrics |
| Consistency | No matter where you look in the database, you won't find any contradictions in your data. | Your payment system shows that Jane Brown has made 5 purchases this month, and the CRM system contains the same information. | Your payment system shows that Jane Brown has made 5 purchases this month, while the CRM system shows she has made only 4. | The number of inconsistencies. |
| Accuracy | The information your data contains corresponds to reality. | Your customer's name is Jane Brown, and this is exactly how it is reflected in the CRM. | In the CRM, your customer's name is spelled as Jane Brawn, though her actual name is Jane Brown. | The ratio of data to errors. |
| Completeness | All the available elements of the data have found their way to the database. | You know that Jane Brown was born on 11/04/1975. | You have no idea how old Jane Brown is as the data of birth cell is empty. | The number of missing values. |
| Auditability | Data is accessible and it is possible to trace introduced changes. | You can track down changes made is Jane's data record. For example, on 12/5/2024, her phone number was changed. | It's impossible to trace down the changes in Jane's record. | % of cells where the metadata about introduced changes is not accessible. |
| Orderliness | The data entered has the required format and structure. | The entry for December 11, 2018 is in the format 12/11/2018. | The entry for December 11, 2018 is in the formats 12/11/18, 12/11/2018, and even 11/12/18 (in your European stores). | The ratio of data of an inappropriate format. |
| Uniqueness | A data record with specific details appears only once in the database. | You have only one record for Jane Brown, born on 11/04/1975, who lives in Seattle. | You have multiple duplicate records for Jane Brown. | The number of duplicates revealed. |
| Timeliness | Data represents reality within a reasonable period of time or in accordance with corporate standards. | On 02/15/2020, the customer informed you that her name is misspelled in the emails you send her. The customer's name was corrected the next day. | On 02/15/2020, the customer informed you that her name is misspelled in the emails you send her. Her name was corrected only in a month. | The number of records with delayed changes. |
An important remark: for big data, not all the parameters are 100% achievable. So, if you deal with big data, you may be interested in checking the specifics of big data quality management.
Why Low Data Quality is a Problem
Now, let’s consider a few examples to see what impact low-quality data can have on business processes.
Unreliable info
A manufacturer thinks that they know the exact location of the truck transporting their finished products from the production site to the distribution center. They optimize routing, estimate delivery time, etc. And it turns out that the location data is wrong. The truck arrives later, which disrupts the normal flow at the distribution center. Not to mention routing recommendations that turned out useless.
Incomplete data
Say, you are working to optimize your supply chain management. To assess suppliers and understand which ones are disciplined and trustworthy and which ones are not, you track the delivery time. But unlike scheduled delivery time, the actual delivery time parameter is not mandatory in your system. Naturally, your warehouse employees usually forget to key it in. Not knowing this critical information (having incomplete data), you fail to understand how your suppliers perform.
Ambiguous data interpretation
A machinery maintenance system may have a field called “Breakdown reason” intended to help identify what caused the failure. Usually, it takes the form of a drop-down menu and includes the “Other” option. As a result, a weekly report may say that in 80% of cases the machinery failure was caused by the “Other” reason. Thus, a manufacturer can experience low overall equipment efficiency without being able to learn how to improve it.
Duplicated data
At a first glance, duplicated data may not pose a challenge. But in fact, it can become a serious issue. For example, if a customer appears more than once in your CRM, this not only takes up additional storage but also leads to a wrong customer count. Additionally, duplicated data weakens marketing analysis: it disintegrates a customer’s purchasing history and, consequently, makes the company unable to understand customer needs and segment customers properly.
Outdated information
Imagine that a customer once completed a retailer’s questionnaire and stated that they did not have children. However, time passed – and now they have a newborn baby. The happy parents are ready to spend their budget on diapers, baby food, and clothes, but is our retailer aware of that? Is this customer included in “Customers with babies” segment? No to both. This is how obsolete data may result in wrong customer segmentation, poor knowledge of the market, and lost profit.
Late data entry/update
Late data entries and updates may negatively affect data analysis and reporting, as well as your business processes. An invoice sent to the wrong address is a typical example to illustrate the case. And to spice the story up even more, here’s another example on asset tracking. The system can state that the cement mixer is unavailable at the moment only because the responsible employee is several hours late with updating its status.
Data Quality Management Best Practices
As the consequences of poor data quality can appear disruptive, it’s critical to learn what the remedies are. Here, we share best practices that can help you establish a well-organized data quality management process.
-
Making data quality a priority
The first step is to make data quality improvement a high priority and ensure that every employee understands the problems that low data quality brings. Sounds quite simple. However, incorporating data quality management into business processes requires multiple serious steps:
- Designing an enterprise-wide data strategy.
- Creating clear user roles with rights and accountability.
- Setting up a data quality management process (we’ll explain it in detail later in the article).
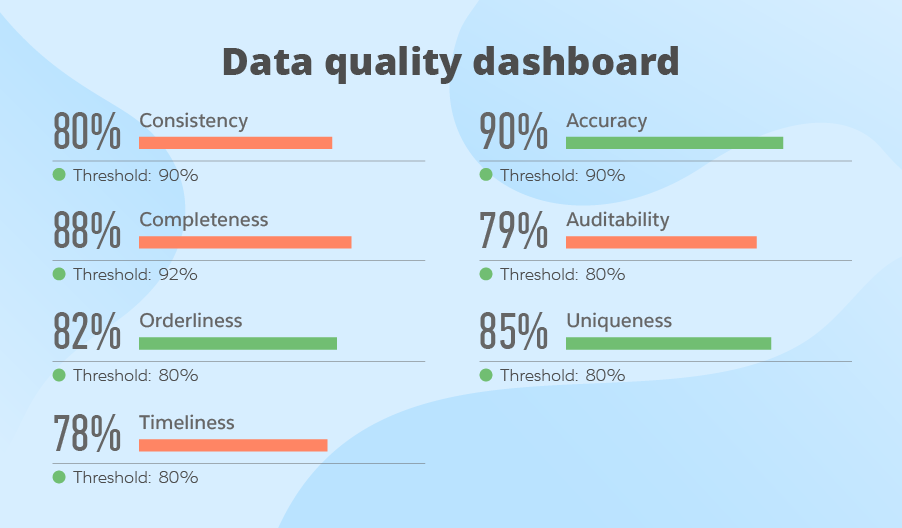
- Having a dashboard to monitor the status quo.
-
Automating data entry
A typical root cause for poor data quality is manual data entries: by employees, by customers or even by multiple users. Thus, companies should think how to automate data entry processes in order to reduce human error. Whenever the system can do something automatically (for example, autocompletes, call or e-mail logs), it is worth implementing.
One of the ways to achieve automation (and not only for data entry) is to use AI-powered tools. They can be utilized for data cleansing, anomaly detection, and continuous data quality monitoring. According to an Ataccama report, 74% of surveyed organizations have already implemented some AI solution for data quality management, and 33% have adopted such tools at an enterprise scale.
-
Preventing duplicates, not just curing them
A well-known truth is that it is easier to prevent a disease than cure it. You can treat duplicates in the same way! On the one hand, you can just regularly clean them. On the other hand, you can create duplicate detection rules. They allow identifying that a similar entry already exists in the database and forbid creating another one or suggest merging the entries.
-
Taking care of both master and metadata
Nursing your master data is extremely important, but you shouldn’t forget about your metadata either. For example, without time stamps that metadata reveals, companies won’t be able to control data versions. As a result, they could extract obsolete values for their reports, instead of updated ones.
Data Quality Management: Process Stages Described
Data quality management is a setup process, which is aimed at achieving and maintaining high data quality. Its main stages involve the definition of data quality thresholds and rules, data quality assessment, data quality issues resolution, data monitoring and control.
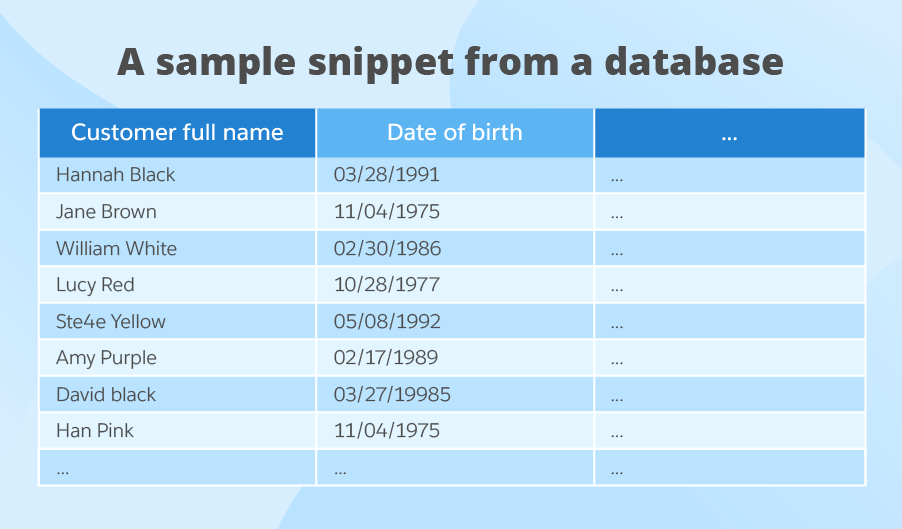
To provide as clear an explanation as possible, we’ll go beyond theory and explain each stage with an example based on customer data. Here is a sample snippet from a database:
1. Define data quality thresholds and rules
If you think there’s only one option – perfect data that is 100% compliant with all data quality attributes (in other words, 100% consistent, 100% accurate, and so on) – you may be surprised to know that there are more scenarios than that. First, reaching 100% everywhere is an extremely cost- and effort-intensive endeavor, so normally companies decide what data is critical and focus on several data quality attributes that are most applicable to this data. Second, a company not always needs 100% perfect data quality, sometimes they can do with the level that is ‘good enough.’ Third, if you need various levels of quality for various data, you may set various thresholds for different fields. Now, you may have a question: how to measure if the data meets these thresholds or not? For that, you should set data quality rules.
Now, when the theory part is over, we’re switching to a practical example.
Say, you decide that the customer full name field is critical for you, and you set a 98% quality threshold for it, while the date of birth field is of lesser importance, and you’ll be satisfied with 80% threshold. As a next step, you decide that customer full name must be complete and accurate, and the date of birth must be valid (that is to say, it should comply with the orderliness attribute). As you’ve chosen several data quality attributes for the customer full name, all of them should hit a 98% quality threshold.
Now you set data quality rules that you think will cover all the chosen data quality attributes. In our case, these are the following:
- Customer full name must not be N/A (to check completeness).
- Customer full name must include at least one space (to check accuracy).
- Customer name must consist only of letters, no figures allowed (to check accuracy).
- Only first letters in customer name, middle name (if any) and surname must be capitalized (to check accuracy).
- Date of birth must be a valid date that falls into the interval from 01/01/1900 to 01/01/2010.
2. Assess the quality of data
Now, it’s time to have a look at our data and check whether it meets the rules we set. So, we start profiling data or, in other words, getting statistical information about it. That’s how it works: we have 8 individual records (although your real data set is certainly much bigger than that) that we check against our first rule Customer full name must not be N/A. All the records comply with the rule, which means that data is 100% complete.
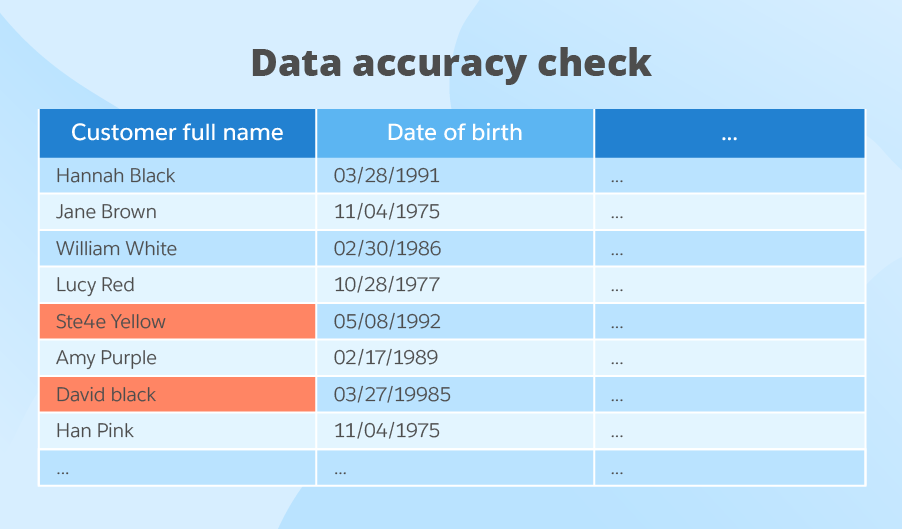
To measure data accuracy, we have 3 rules:
- Customer full name must include at least one space.
- Customer name must consist only of letters, no figures allowed.
- Only first letters in customer name, middle name (if any) and surname must be capitalized.
Again, we do data profiling, for each of the rules, and we get the following results: 100%, 88% and 88% (below, we’ve highlighted the records non-compliant to the data accuracy rule). In total, we have only 92%, which is also under our 98% threshold.
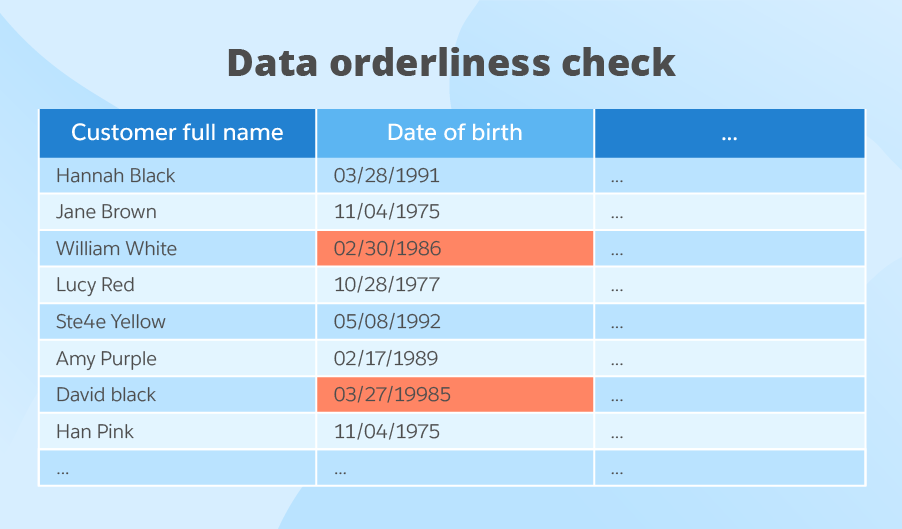
As for the date of birth field, we’ve identified two data records that don’t comply with the rule we set. So, data quality for this field is as high as 75%, which is also below the threshold.
3. Resolve data quality issues
At this stage, we should think what caused the issues to eliminate their root cause. In our example, we identified several problems for the customer full name field that can be solved by introducing clear standards for manual data entries, as well as data quality-related key performance indicators for the employees responsible for keying data into a CRM system.
In the example with the date of birth field, the data entered was not validated against the date format or range. As a temporary measure, we clean and standardize the data. But to avoid such mistakes in the future, we should set a validation rule in the system that will not accept a date unless it complies with the format and range.
4. Monitor and control data
Data quality management is not a one-time effort, rather a non-stop process. You need to regularly review data quality policies and rules with the intent to continuously improve them. This is a must, as the business environment is constantly changing. Say, one day a company may opt for enriching their customer data by purchasing and integrating an external data set that contains demographic data. So, probably, they’ll have to come up with new data quality rules, as an external data set can contain the data they haven’t dealt with so far.
Categories of Data Quality Tools
To address various data quality issues, companies should consider not one tool but a combination of them. For example, Gartner names the following categories:
- Parsing and standardization tools break the data into components and bring them to a unified format.
- Cleaning tools remove incorrect or duplicated data entries or modify the values to meet certain rules and standards.
- Matching tools integrate or merge closely related data records.
- Profiling tools gather stats about data and later use it for data quality assessment.
- Monitoring tools control the status-quo of data quality.
- Enrichment tools bring in external data and integrate it into the existing data.
Currently, the market can boast a long list of data quality management tools. The trick is that some of them focus on a certain category of data quality issues, while others cover several aspects. According to 6sense, over 95,000 companies worldwide use data quality management tools nowadays, and a report by Precisely indicates that businesses use these tools for different functions, including data cleansing, data profiling, anomaly detection, data quality metrics monitoring, and more. To pick the right tools, you should either dedicate significant time to research or let professional consultants do this job for you.
Boundless Data Quality Management Squeezed Into One Paragraph
Data quality management guards you from low-quality data that can totally discredit your data analytics efforts. However, to do data quality management right, you should keep in mind many aspects. Choosing the metrics to assess data quality, selecting the tools, and describing data quality rules and thresholds are just several important steps. Hopefully, this complicated task can be fulfilled with professional assistance. At ScienceSoft, we are happy to back up your data quality management project at any stage, just let us know.
