Demand Forecasting Using Traditional and Contemporary Data Science

Related topics:
Last updated:
From our consulting practice, we know that even the companies that have put significant effort into demand forecasting can still go the extra mile and improve the accuracy of their predictions. So, if you’re one of the companies who want reliable demand forecasts on their radars, this is the right page for you.
Though a 100% precision is impossible to achieve, we believe data science can get you closer to it, and we’ll show how. Our data scientists have chosen the most prominent demand forecasting methods based on both traditional and contemporary data science to show you how they work and what their strengths and limitations are. We hope that our overview will help you opt for the right method, which is one of the essential steps to creating a powerful demand forecasting solution.

Traditional data science: The ARIMA model
A well-known traditional data science method is the autoregressive integrated moving average (ARIMA) model. As the name suggests, its main parameters are autoregressive order (AR), integration order (I) and moving average order (MA).
The AR parameter identifies how the values of the previous period influence the values of the current period. For example, tomorrow the sales for SKU X will be high if the sales for SKU X were high during the last three days.
The I parameter defines how the difference in the values of the previous period influence the value in the current period: tomorrow the sales for SKU X will be the same if the difference in sales for SKU X was minimal during the last three days.
The MA parameter identifies the model’s error based on all the observed errors in its forecasts.
Strengths of the ARIMA model
- ARIMA works well when the forecast horizon is short-term and when the number of demand-influencing factors is limited.
Limitations of the ARIMA model
- ARIMA is unlikely to produce accurate long-term forecasts as it doesn’t store insights for long time periods.
- ARIMA assumes that your data doesn’t show any trend or seasonal fluctuations, while these conditions are sure not to be met in real life.
- ARIMA requires extensive feature engineering efforts to capture root causes of data fluctuations and that is a lengthy and labor-intensive process. For example, a data scientist should mark particular days of the month as weekends for ARIMA to take into account this factor. Otherwise, it won’t recognize the impact of a particular day on sales.
- The model can be time-consuming as every SKU or subcategory requires separate tuning.
- It can only handle numerical data, such as sales values. This means that you can’t take into account such factors as weather, store type, store location and promotion influence.
- It fails to capture non-linear dependencies, and that’s the kind of dependencies that is most frequent. For example, with 5% off promotion, toys from Frozen witnessed a 3% increase in sales. If the discount becomes twice higher – 10%, this doesn’t mean that the company should expect a double increase in sales to 6%. Besides, if they run a 5% promotion for Barbie dolls, their sales can increase by 9% as promotion influences various categories differently.
Contemporary data science: Deep neural networks
Since there are so many limitations to traditional data science, it’s natural that there are other, more reliable approaches, namely contemporary data science. There’s no better candidate to represent contemporary data science than a deep neural network (DNN). Recent research papers show that DNNs outperform all the other forecasting approaches in terms of effectiveness and accuracy of predictions. To usher you into the promising world of deep learning, our data scientists composed a 5-minute introduction to DNNs that comprises both the theory part and the practical example.
What are DNNs made of?
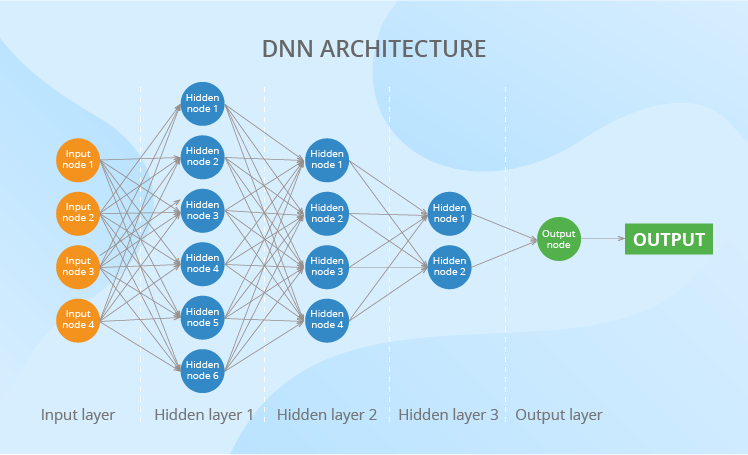
Here’s the architecture of a standard DNN. To read this scheme, you should know just 2 terms – a neuron and a weight. Neurons (also called ‘nodes’) are the main building blocks of a neural network. They are organized in layers to transmit the data along the net, from its input layer all the way to the output one.
As to the weights, you can regard them as coefficients applied to the values produced by the neurons of the previous layer. Weights are of extreme importance as they transform the data along its way through a DNN, thus influencing the output. The more layers a DNN has or the more neurons each layer contains, the more weights appear.
What data can DNNs analyze?
DNNs can deal equally well with numerical and categorical values. In the case with numerical values, you give the network all needed figures. And in case with categorical values, you’ll need to use ‘0-1’ language. It usually works like this: if you want to input a particular day of the week (say, Wednesday), you should have seven neurons, and you’ll give 1 to the third neuron (which will mean Wednesday) and zeroes to all the rest.
The vast diversity of data that a DNN is able to ingest and analyze allows considering multiple factors that can influence demand, thus improving the accuracy of forecasts. The factors can be internal, such as store location, store type and promotion influence, and external ones – weather, changes in GDP, inflation rate, average income rate, etc.
And now, a practical example. Say, you are a manufacturer who uses deep neural networks to forecast weekly demand for their finished goods. Then, you may choose the following diverse factors and data for analysis.
| Factors to analyze | What each factor reflects | Number of neurons for the input layer |
| 8 previous weeks’ sales figures | Latest trends | 8 |
| Weeks of the year | Seasonality | 52 (according to the number of weeks in a year) |
| SKUs | Patterns specific to each SKU | 119 (according to the number of SKUs in your product portfolio) |
| Promotion | The influence of promotion | 1 (Yes or No) |
| Total number of input neurons: 180 |
In addition to showing the diversity of data, the table also draws the connection between the business and technical aspects of the demand forecasting task. Here, you can see how factors are finally converted into neurons. This information will be useful for understanding the sections that follow.
Where does DNN intelligence come from?
There are two ways for a DNN to get intelligence, and they peacefully coexist. Firstly, this intelligence comes from data scientists who set the network’s hyperparameters and choose most suitable activation functions. Secondly, to put its weights right, a DNN learns from its mistakes.
Activation functions
Each neuron has an activation function at its core. The functions are diverse and each of them takes a different approach to converting the values they take in. Therefore, different activation functions can reveal various complex linear and non-linear dependencies. To ensure the accuracy of demand forecasts and not to miss or misinterpret exponential growth or decline, surges and temporary falls, waves, and other patterns that data shows, data scientists carefully choose the best set of activation functions for each case.
Hyperparameters
There are dozens of hyperparameters, but we’d like to focus on a more down-to-earth one, such as the number of hidden layers required. Choosing this parameter right is critical for making a DNN able to identify complex dependencies. The more layers, the more complex dependencies a DNN can recognize. Each business task, and consequently, each DNN architecture designed to solve this task, requires an individual approach to the number of its hidden layers.
Suppose in our example, data scientists decided that the neural network requires 3 hidden layers. They also came up with the coefficients that change the number of neurons in the hidden layers (these coefficients are always applied to the number of neurons in the input layer). Here are their findings:
| Layer | Coefficient | Number of neurons in the layer |
|---|---|---|
| Input layer | 180 | |
| Hidden layer 1 | 1.5 | 270 |
| Hidden layer 2 | 1 | 180 |
| Hidden layer 3 | 0.5 | 90 |
| Output layer | 1 | |
| Total number of neurons in the network: 721 |
Usually, data scientists create several neural networks and test which one shows better performance and higher accuracy of predictions.
Weights
To work properly, a DNN should learn which of its actions is right and which one is wrong. Let’s look at how the network learns to set the weights right. At this stage, regard it as a toddler who learns from their personal experience and with some supervision of their parents.
The network takes the inputs from your training data set. This data set is, in fact, your historical sales data broken down to SKU and store level, which may also contain store attributes, prices, promotions, etc. Then, the network lets this data pass through its layers. And, at first, it applies random weights to it and uses predefined activation functions.
However, the network doesn’t stop when it produces an output – a weekly demand for SKU X. Instead, it uses loss function to calculate to which extent the output the network got differs from the one that your historical data shows. Then, the network triggers optimization algorithms to reassign the weights and starts the whole process from the very beginning. The network repeats this as many times (can be thousands and millions) as needed to minimize the mistake and produce an optimal demand.
To let you understand the scale of it all: the number of weights that a neural network tunes can reach hundreds of thousands. In our example, we’ll deal with 113,490 weights. No serious math is required to get this figure. You should just multiply the number of neurons in one layer by the number of neurons in the layer that follows and sum it all up: 180x270 + 270x180 + 180x90 + 90x1 = 113,490. Impressive, right?
Demand forecasting challenges that DNNs overcome
New product introduction
Challenge: Historical data is either limited or doesn’t exist at all.
Solution: A DNN allows clustering SKUs to find lookalikes (for instance, based on their prices, product attributes or appearance) and use their sales histories to bootstrap forecasting.
The thing is that you have all the historical data for the lookalikes because they are your tried-and-tested SKUs. So, you can take their weekly sales data and use it as a training data set to estimate the demand for a new product. As discussed earlier, you can also add external data to increase the accuracy of demand predictions – for example, social media data.
Another scenario here could be: a DNN is tuned to cluster new products according to their performance. This helps to predict how a newly launched product will perform based on its behavior at the earliest stages compared to the behavior of other new product launches.
Complex seasonality
Challenge: For some products (like skis for the winter or sunbathing suits for the summer), the seasonality is obvious, while for others, the patterns are not so easy to spot. If you are looking for multiple seasonal periods or high-frequency seasonality, you need something more efficient than trivial methods.
Solution: Just like with new product introductions, the task of identifying complex seasonality can be solved with the help of clustering. A DNN sifts through hundreds and thousands of sales patterns of each SKU to find similar ones. If particular SKUs belong to the same cluster, they are likely to show the same sales patterns in the future.
Weighing the pros and cons of DNNs
Now that we know how a DNN works, we can consider the upsides and downsides of this method.
Strengths of DNNs
Compared to traditional data science approaches, DNNs can:
- Consider multiple factors based on diverse data (both external and internal, numerical and categorical), thus increasing the accuracy of forecasts.
- Capture complex dependencies in data (both linear and non-linear) thanks to multiple activation functions embedded into the neurons and cleverly set weights.
- Successfully solve typical demand forecasting challenges, such as new product introductions and complex seasonality.
Limitations of DNNs
Although DNNs are the smartest data science method for demand forecasting, they still have some limitations:
- DNNs don’t choose analysis factors on their own. If a data scientist disregards some factor, a DNN won’t know of its influence on the demand.
- DNNs are greedy for data to learn from. The size of the training data set should not be less than the number of weights. And, as we have already discussed, you can easily end up with hundreds of thousands of weights. Correspondingly, you’ll need as many data records.
- If a DNN is trained incorrectly, it can fail to distinguish erroneous data from the meaningful signals. As a result, such a network can produce accurate forecasts on the training data but bring up distorted outputs while dealing with new incoming data. This problem is called overfitting, and data scientists can fight it using a dropout technique.
- Non-technical audience tends to perceive DNNs as ‘magic boxes’ that produce ungrounded figures. You should put some effort into making your account managers trust DNNs.
- DNNs still can’t take into account force majeure, like natural disasters, government decisions, etc.
So, where does your heart lie?
From our consulting experience, we see that contemporary data science in most cases outperforms traditional methods, especially when it comes to identifying non-linear dependencies in data. However, this doesn’t mean that traditional data science methods should be completely disregarded. They still can be considered for producing short-term forecasts. For example, recently we successfully delivered sales forecasting for an FMCG manufacturer, where we applied linear regression, ARIMA, median forecasting, and zero forecasting.
